| metaCASE |
|
poslední verze
0.02.0089
|
|
České vysoké učení technické v Praze Fakulta elektrotechnická
Diplomová práce Meta-CASE
nástroj Bc.
Pavel Jareš Vedoucí práce: Doc. Ing. Karel Richta, CSc. Studijní program: Elektrotechnika a informatika strukturovaný magisterský Obor: Informatika a výpočetní technika květen 2008 Poděkování Chtěl bych poděkovat panu Doc. Ing. Karlovi Richtovi, CSc. za vedení a kontrolu při realizaci mé diplomové práce. Prohlášení Prohlašuji, že jsem svou diplomovou práci vypracoval samostatně a použil jsem pouze podklady uvedené v přiloženém seznamu. Nemám závažný důvod proti užití tohoto školního díla ve smyslu §60 Zákona č. 121/2000 Sb., o právu autorském, o právech souvisejících s právem autorským a o změně některých zákonů (autorský zákon). V Písku dne 20. 5. 2008 ................................................................................ Abstract The main purpose
of this thesis is to design and implement pilot version of meta-Case tool. The
thesis includes the summary of already developed meta-models concepts and definition
of new developed concept based on project GOPRR. The main part of
thesis describes design of application and its implementation. The developed
application was implemented in Java language. There is rich GUI for user support
and the scripting functionality is ensured through JavaScript language. Abstrakt Cílem této diplomové práce je navrhnout a implementovat pilotní verzi meta-CASE nástroje. Obsahuje rešerši již vyvinutých konceptů meta-modelů a definici nového inspirovaného projektem GOPRR. Práce se skládá z návrhu aplikace a popisu implementace. Výsledná aplikace je napsána v jazyce Java. Pro definici modelu je určena rozsáhlá podpora GUI a pro funkci skriptovací jazyk JavaScript. Obsah Seznam
obrázků xiii 1 Úvod 1 1.1 CASE nástroj 1 1.2 Meta-CASE nástroj 1 1.3 Rozdíl CASE a meta-CASE nástroje 2 1.4 Využití meta-CASE 3 2 Popis
problému, specifikace cíle 5 2.1 Meta-model 5 2.1.1 CoCoA
(Complex
Covering Aggregation) 5 2.1.2 COMMA
(Common
Object Methodology Metamodel Architecture) 6 2.1.3 OPRR
(Object-Property-Role-Relationship) 6 2.1.4 GOPRR
(Graph-Object-Property-Role-Relationship) 7 2.1.5 MOF
(Meta
Model Facility) 7 2.1.6 NIAM
(Nijssen’s
Information Analysis Methodology) 8 2.2 Architektura aplikace 9 3 Analýza
a návrh řešení 10 3.1 Struktura meta-modelu 10 3.2 Navrhované součásti 10 3.2.1 Struktura
modelu a meta-modelu 12 3.2.2 Vlastnost 13 3.2.3 Element 14 3.2.4 Vztah 14 3.2.5 Role 15 3.2.6 Diagram 15 3.3 Architektura aplikace 16 3.3.1 Potřebné
součásti 17 3.3.2 Framework 18 3.3.3 Vzhled
aplikace 19 3.4 Detailnější popis součástí 20 3.4.1 Grafický
editor 20 3.4.2 Skript 24 3.5 Návrh balíčků a rozložení projektu 25 4 Realizace 26 4.1 Balíček metacase.core 26 4.2 Balíček metacase.core.framework 26 4.3 Balíček metacase.core.framework.gui 26 4.3.1 Třída
AboutDialog 26 4.3.2 Pracovní
okna 27 4.3.3 Třída
JMenuBarFilled 27 4.3.4 MenuContainer,
MenuContainerInterface a MenuContainerDynamic 27 4.3.5 Třída
BaseView 28 4.3.6 Třída
WelcomeScreen 28 4.3.7 Třída
BoxComponent 28 4.3.8 Třída
Print 28 4.3.9 Třída
PrintPreview 29 4.4 Balíček metacase.core.framework.gui.editor 29 4.4.1 PaintInterface,
PaintLayerInterfacase a Moveable 29 4.4.2 Třída
EditorPane 29 4.4.3 ModelContainer,
Diagram, Panel, PanelsTree 29 4.4.4 Inserter
a zděděné třídy 30 4.4.5 Třídy
Element, Relationship, RelationshipLine a End 30 4.4.6 Třída
Rulers 30 4.5 Balíček metacase.core.framework.gui.editor.anchor 31 4.6 Balíček metacase.core.framework.gui.editor.decores 31 4.6.1 Náhledy 31 4.7 Balíček metacase.core.framework.gui.infos 31 4.8 Balíček metacase.core.framework.gui.jtable 32 4.9 Balíček metacase.core.framework.gui.toolbars 32 4.10 Balíček metacase.core.framework.script 33 4.11 Balíček metacase.core.framework.script.editor 33 4.12 Balíček metacase.core.framework.script.exceptions 34 4.13 Balíček metacase.core.framework.script.functions 34 4.14 Balíček metacase.core.framework.script.io 34 4.15 Balíček
metacase.core.framework.script.tokens 34 4.16 Balíček metacase.core.framework.script.variable 34 4.16.1 Třída LexicalAnalyzer 35 4.16.2 Třída SemanticAnalyzer 35 4.16.3 Třída PredefinedCode 35 4.17 Balíček metacase.core.framework.undo 35 4.18 Balíček metacase.core.framework.other 35 4.19 Balíček metacase.core.metamodel 36 4.20 Balíček metacase.core.metamodel.exception 36 4.21 Balíček metacase.core.metamodel.io 36 4.22 Balíček metacase.core.metamodel.propertydata 36 4.23 Balíček metacase.core.metamodel.other 37 5 Testování 38 5.1 Jednotkový test 38 5.2 Integrační testování 38 5.3 Regresivní testování 38 5.4 Validační testování 38 5.5 Useability testování 39 6 Závěr 40 7 Seznam
literatury 41 A Seznam
použitých zkratek 42 B UML
diagramy 43 C Uživatelská
/ instalační příručka 45 D Přílohy
skriptovacího jazyka 77 E Ukázky
schémat vzniklých aplikací metaCASE 86 F Obsah
přiloženého CD 89 Obrázek 1 Rozdíl CASE a meta-CASE nástroje [4]......................................................................................... 2 Obrázek 2 Jiná
terminologie u meta-modelování [3].............................................................................. 3 Obrázek 3
Meta-model stavového modelu pomocí CoCoA [3]........................................................... 6 Obrázek 4
Meta-model stavového modelu pomocí OPRR [3]............................................................... 7 Obrázek 5
Meta-model stavového modelu pomocí GOPRR [3]............................................................ 7 Obrázek 6
Meta-model stavového modelu pomocí NIAM [3]............................................................... 8 Obrázek 7 Vztah
role, vztahu, objektu a vlastnosti....................................................................... 12 Obrázek 8 Ukázka
základních konstrukcí ER-modelu................................................................... 14 Obrázek 9 diagram
tříd modelu a metamodelu.................................................................................... 16 Obrázek 10
Konceptuální model navrhované aplikace................................................................. 18 Obrázek 11
Navrhovaný vzhled (rozvržení úvodní obrazovky meta-CASE nástroje) 20 Obrázek 12 Třída v
UML............................................................................................................................................ 21 Obrázek 13
Znázornění příkladu použití panelů (element třídy v UML)............................. 22 Obrázek 14 Ukázka
struktury grafické reprezentace (vlastnost vzhledu)................ 22 Obrázek 15 Diagram
tříd – Inserter............................................................................................................... 43 Obrázek 18 Diagram
tříd - rozdělení tokenů do kategorií.......................................................... 43 Obrázek 16 Diagram
tříd dekorací................................................................................................................. 44 Obrázek 17 Diagram
tříd balíčku metacase.core.framework.gui.infos........................... 44 Obrázek 19 Úvodní
stránka.................................................................................................................................. 45 Obrázek 20
Konktextové menu - pracovní okna.................................................................................... 46 Obrázek 21
Průzkumník metamodelu........................................................................................................... 46 Obrázek 22
Průzkumník modelu........................................................................................................................ 47 Obrázek 23
Průzkumník prvků modelu........................................................................................................ 47 Obrázek 24
Průzkumník vlastností................................................................................................................ 48 Obrázek 25 Editor
složitějších datových typů..................................................................................... 48 Obrázek 26
Průzkumník metavlastností................................................................................................... 48 Obrázek 27
Průzkumník panelů návrhu...................................................................................................... 49 Obrázek 28 Konzole.................................................................................................................................................... 49 Obrázek 29
Průzkumník modelů........................................................................................................................ 50 Obrázek 30 Panely
nástrojů................................................................................................................................. 50 Obrázek 31
Standardní panel nástrojů....................................................................................................... 51 Obrázek 32 Panel
nástrojů – dekorace........................................................................................................ 51 Obrázek 33 Ukázka
návrhu zakončení........................................................................................................ 51 Obrázek 34 Panel
nástrojů - bod, vektor.................................................................................................... 51 Obrázek 35 Panel
nástrojů - vzad, vpřed,.................................................................................................... 51 Obrázek 36 Panel
nástrojů – přiblížení....................................................................................................... 51 Obrázek 37 Panel
nástrojů – font..................................................................................................................... 52 Obrázek 38 Panel
nástrojů – interpret........................................................................................................ 52 Obrázek 39
Roletové menu.................................................................................................................................... 52 Obrázek 40 Nabídka
soubor.................................................................................................................................. 52 Obrázek 41 Nabídka
soubor - import.............................................................................................................. 53 Obrázek 42 Nabídka
soubor-export................................................................................................................ 53 Obrázek 43 Nabídka
zobrazit.............................................................................................................................. 53 Obrázek 44 Nabídka
zobrazení........................................................................................................................... 54 Obrázek 45 Nabídka
zobrazit - panely nástrojů................................................................................... 54 Obrázek 46 Panel
zobrazit - pracovní okna............................................................................................. 54 Obrázek 47 Nabídka
vložit.................................................................................................................................... 55 Obrázek 48 Nabídka
vložit - dekorace......................................................................................................... 55 Obrázek 49 Nabídka
O programu....................................................................................................................... 55 Obrázek 50 Náhled
metamodelu....................................................................................................................... 56 Obrázek 51 Náhled
vztahu.................................................................................................................................... 56 Obrázek 52
Pravítka.................................................................................................................................................. 57 Obrázek 53 Náhled
tisku......................................................................................................................................... 57 Obrázek 54 Otevření
editoru kódu................................................................................................................. 59 Obrázek 55 Ukázka
ER-schéma............................................................................................................................ 86 Obrázek 56 Ukázka
schéma use-case............................................................................................................. 87 Obrázek 57 Ukázka
drigramu tříd.................................................................................................................. 88
Tabulka 1 Pracovní okna....................................................................................................................................... 27 Tabulka 2
Parametry MenuContainer typu String............................................................................. 27 Tabulka 3 Základní
metody EditorPane..................................................................................................... 29 Tabulka 4 Účel
tříd dědících třídu Inserter......................................................................................... 30 Tabulka 6 Způsoby
přichycení............................................................................................................................ 31 Tabulka 7 Dekorace................................................................................................................................................... 31 Tabulka 9 Náhledy...................................................................................................................................................... 31 Tabulka 10
Renderery a editory pro PropertyData.......................................................................... 32 Tabulka 11 Panely
nástrojů................................................................................................................................. 33 Tabulka 12 Výjimky
používané pro skriptování.................................................................................... 34 Tabulka 13 Datové
typy........................................................................................................................................... 34 Tabulka 14 Důležité
metody třídy SemanticAnalyzer................................................................... 35 Tabulka 15 Třídy
balíčku metacase.core.framework.other.................................................... 36 Tabulka 16 Datové
typy - PropertyData...................................................................................................... 37 1 ÚvodCílem práce je navrhnout a implementovat meta-CASE nástroj, který je programovatelný popisem použitého modelu – meta-modelem. Meta-CASE nástroj navazuje na linii CASE nástrojů a rozšiřuje je. Každá diplomová práce by měla začínat rozborem problematiky a definovat základní kameny, proto je první část zaměřena na definici pojmů a vysvětlení užití meta-CASE nástrojů. Dále pokračuje rozbor problematiky a nastínění možných způsobů implementace. V další části je uveden návrh struktur pro implementaci. Následující kapitola je zaměřena na analytickou část, tzn. architektonický a softwarový návrh. Na konec je popsána samotná implementace. Zde je podrobně zmapována architektura, technologie, návrhové vzory a jednotlivá rozhraní použitá v implementaci. Přílohy jsou na přiloženém CD. Důležité materiály naleznete i na konci mé diplomové práce. 1.1 CASE nástrojZpůsob vývoje aplikací se v průběhu let vyvíjel. Na začátku vznikaly programy bez podpory vývojového prostředí. Snahou vývojářů nebylo vždy jen vyvíjet aplikace pro koncové uživatele, ale zároveň podpořit samotný návrh a realizaci softwaru. Postupně se zaváděly různé metodiky. Ty pomocí různých modelů snadno a přehledně popisovaly dílčí části softwaru. To byl impuls pro vývojáře vytvořit první CASE (Computer-aided software engineering) nástroj. CASE nástroj umožní uživateli vytvořit schéma, a poté na základě něj vygenerovat požadovaná data. Může se jednat o kus kódu nebo dokonce o celou aplikaci. CASE nástroj může značně urychlit vývoj, avšak mívá i řadu nevýhod a omezení. Existuje jich celá řada a každý je uzpůsoben k jiné činnosti (některé umí pouze UML, jiné ER-modely atd.). Uživatel si pořídí CASE nástroj a může v něm modelovat pouze s prvky a vazbami, který tento software nabízí. Není dovoleno vytvářet nové, upravovat stávající, ani definovat vlastní modely. Samotné rozšiřování se může lišit i v exportu dat. Poměrně často vývojář vytvoří schéma a potřebuje různé exporty. Např. pro databáze základní export sestaví skript, který vytvoří databázi, jednotlivé tabulky a definuje vztahy mezi nimi (primární a cizí klíče, indexy apod.). Řada CASE nástrojů umožňuje jen určitou množinu derivací SQL jazyka, a tak se často stává, že výstupem je skript pro jiný databázový stroj. Ten je nejprve nutné upravit a až poté ho lze použít. To značně snižuje výhody použití. Pokud by však uživatel mohl dodefinovat nějaký z exportů, byla by aplikace pro něj více žádaná. Proto se v posledních letech objevuje nová možnost modelování a sice meta-CASE nástroje. 1.2 Meta-CASE nástrojJak již bylo naznačeno meta-CASE nástroj je aplikace, která dovoluje nadefinovat model (jaké prvky obsahuje, jak vypadají, jaké vazby lze realizovat a co znamenají) a poté vytvořit samotné importy a exporty. Tím vznikne CASE nástroj přesně podle požadavků vývojáře. Nyní může tento nástroj používat, vytvářet schémata a ty poté převádět do potřebného kódu. Meta-CASE nástroj lze tedy chápat jako CASE nástroj, který je použitelný pro více pro více modelů s možností úprav a definice nových, ale také jako aplikaci, určenou pro vytváření CASE nástrojů. Oba pohledy v praxi představují to samé. Rozdíl spočívá pouze ve způsobu vytváření schémat. Buď se modeluje přímo pomocí meta-CASE nástroje, nebo v aplikaci, která je vytvořena pro každý model zvlášť. Vzhledem k tomu, že meta-CASE nástroje je možné upravit pro nějaký jiný model a lze vytvořit i výstup, bývají někdy označovány jako CAME (Computer-aided Method Engineering). 1.3 Rozdíl CASE a meta-CASE nástrojeRozdíl klasického CASE nástroje od meta-CASE je tedy vcelku jednoduchý. CASE nástroj je oproti meta-CASE tzv. „zadrátovaný“. To znamená, že CASE nástroj umí pouze jazyk, pro který je určen a není použitelný pro jiný model. V meta-CASE nástroji však uživatel vytváří meta-model, který odpovídá onomu „zadrátovanému“ jazyku v CASE nástroji a s tím poté pracuje. Meta-CASE tedy nahrazuje nemodifikovatelnou definici modelu meta-modelem (viz Obrázek 1). Ten je řízen jen za pomoci zobecněných pravidel – meta-modelujícím jazykem. V něm meta-modelář vytvoří konkrétní meta-model, na základě kterého je možné vytvářet schémata (viz models).
Obrázek 1 Rozdíl CASE a meta-CASE nástroje [4] Někdy se v rámci různých terminologií mluví o tzv. meta-meta-modelu. Zde je jako meta-meta-model označena vrstva, ve které se utváří meta-model, odpovídající CASE nástroji. Meta-modelovací jazyk umožňuje práci s meta-modelem (vytvoření meta-modelu a jeho správu). Meta-model definuje možné prvky a jejich vazby. Na základě těchto pravidel je vytvářen model. Ten odpovídá schématu v CASE nástroji. Jako meta-meta-model je označena vrstva, udržující informaci o
meta-modelu (viz 2.1).
Obrázek 2 Jiná terminologie u meta-modelování [3] Obrázek 2 zobrazuje jiný pohled na meta-CASE nástroje. 1.4 Využití meta-CASEMeta-CASE se vyvíjí v zásadě ze dvou důvodů: - jako produkt pro cílového zákazníka - interní verze vytvářeného CASE nástroje Na trhu meta-CASE nástroj není častý, protože cílová skupina uživatelů schopná vytvářet nové a upravovat staré metodiky je poměrně malá. I přesto je možné takovou aplikaci získat. K nejznámějším patří MetaEdit+ (http://www.metacase.com). Druhá varianta je mnohem častější. Vývojáři CASE nástrojů často vyvíjí meta-CASE, ale před vydáním z něj vytvoří klasický CASE nástroj. Tím zvyšují prodejnost nových verzí. Inovace je pro ně mnohem jednodušší a nemusí řadu změn dělat přímo ve zdrojovém kódu, ale stačí pouze změnit meta-model. Společné prvky, které obsahuje každý z CASE nástrojů, mění (přidávají) jednotně. Tím dosahují vyšší produktivity a zároveň snižují počet chyb. 2 Popis problému, specifikace cíleCílem práce je navrhnout a implementovat meta-CASE nástroj. Samotný návrh se skládá ze dvou hlavních částí. Je nutné navrhnout především způsob uložení a spravování dat v rámci meta-modelu a dále rozvržení aplikace jako takové. Návrh aplikace musí respektovat rozšiřitelnost a modifikovatelnost, jak na úrovni aplikace (uživatelským vstupem), tak i na úrovni kódu (předpokladem je, že vznikne aplikace, která bude obsahovat základní části a pro její široce použitelnou verzi bude nutný další rozvoj). 2.1 Meta-modelNávrh meta-modelu je stěžejní částí práce. Koncept uložení dat je základní částí, a proto je vhodné, aby nedocházelo v průběhu vývoje k velkým změnám. Veškeré součásti aplikace (import, export, správa dat, algoritmy pro práci s grafy, GUI a další) budou od prvních sestavení využívat meta-model a tak každá jeho úprava může představovat opravu celého projektu. Z těchto důvodů je vhodné nejen správně navrhnout strukturu, ale dbát i na robustnost. Tzn. vytvořit abstraktní model spolu s mnoha rutinami tak, aby jednotlivé součásti aplikace nepřistupovaly přímo k datům, ale přistupovaly k datům prostřednictvím metod pomocných tříd. Tím se do značné míry odstíní samotné uložení dat a jejich užití. Díky tomu bude teoreticky možné zaměnit i samotnou strukturu (bude-li to v budoucnu nutné) a zachovat zpětnou kompatibilitu. Tento projekt nevyžaduje žádné konkrétní struktury, nicméně výzkum v této oblasti nabízí řadu popsaných implementací. Proto se dále zaměřím na již navržené řešení a v další kapitole (3) popíši svůj návrh. Nebude se tedy jednat o převzatý koncept, ale o vlastní způsob řešení inspirovaný ověřenými modely: - CoCoA (Complex Covering Aggregation) - COMMA (Common Object Methodology Metamodel Architecture) - OPRR (Object-Property-Role-Relationship) - GOPRR (Graph-Object-Property-Role-Relationship) - MOF (Meta Model Facility) - NIAM (Nijssen’s Information Analysis Methodology) 2.1.1 CoCoA (Complex Covering Aggregation)CoCoA byl vyvinut pro podporu konceptuálních modelů a pro datové modelování komplexních problémů. Zahrnuje: - entity (entities) - pojmenované relace (names relationships) - n-ární relace (n-ary relationships) - alternativní pojmenování (alias name) - kategorie entit (entity categories)
Obrázek 3 Meta-model stavového modelu pomocí CoCoA [3] 2.1.2 COMMA (Common Object Methodology Metamodel Architecture)Projekt COMMA se snažil vytipovat společné prvky všech objektově orientovaných metodik a ty následně reprezentovat jako základní pojmy meta-modelu a tím vytvořit meta-modely nejrozšířenějších objektově orientovaných metodik. Používá tyto základní pojmy: - pojem (concept) – má jméno a atributy - dědění (inheritance) – vyjadřuje relaci specializace - asociace (association) – vyjadřuje vztah mezi pojmy - agregace (aggregation) – vyjadřuje skládání, je to speciální případ asociace - role (role) – objevuje se, když objekt přijímá charakteristiky jiného objektu. Role je dočasná a objekt může mít i více rolí najednou. Projekt vyprodukoval velmi jednoduchý ale mocný objektově orientovaný meta-modelovací jazyk. Současnou nevýhodou je, že neexistuje napojení na CASE nástroje (projekt byl již ukončen). 2.1.3 OPRR (Object-Property-Role-Relationship)Model OPRR byl vyvinut pány Welke a Smolander. Jazyk je zaměřen na modelovací techniky od základních po specifické. Rozšiřuje ER-model o roli (role). Ta je reprezentována kružnicí a rozděluje model na části se společnými vlastnostmi.
Obrázek 4 Meta-model stavového modelu pomocí OPRR [3] 2.1.4 GOPRR (Graph-Object-Property-Role-Relationship)Jazyk pro meta-modelování GOPRR vznikl rozšířením jazyka OPRR jako součást disertační práce pana Kellyho. Úkolem bylo vytvořit s pomocí GOPRR CAME nástroj MetaEdit+. Základními prvky GOPRR jsou: - diagram (graph) – je kolekce objektů, vztahů a rolí, která definuje, co a jak lze spojovat dohromady - objekt (object) – definuje entitu, která může existovat samostatně - vlastnost (property) – charakterizuje graf, objekt, roli nebo vztah - vztah (relationship) – existuje mezi dvěma a více objekty - role (role) – existuje mezi vztahem a objektem
Obrázek 5 Meta-model stavového modelu pomocí GOPRR [3] 2.1.5 MOF (Meta Model Facility)Jedná se o standard vyvinutý OMG (Object Management Group) pro meta-meta-model. Spolu s jazykem UML (Unified Modeling Langue) a konverzním prostředkem XMI (XML Metadata Interchange) tvoří tzv. modelem řízenou architekturu MDA (Model Driven Architecture). MOF, UML a XMI jsou určeny pro různé části aplikace. Zatímco MOF popisuje meta-meta-model, UML je využíváno na úrovni meta-modelu (vizualizace), XMI se používá pro mapování MOF do XML. Tím je možná výměna meta-modelů a jejich instancí. Základní prvky MOF jsou: - třída (class) – určená pro definování různých meta-dat - asociace (association) – slouží k definování binárních relací mezi třídami. Má 2 zakončení (association end) obsahující jméno (name), typ (type), násobnost (multiplicity) a agregaci (aggregation). - typ dat (data types) – jsou navrženy k určení typů meta-dat, která nemají objektovou identitu (možnost modelovat jako objekty nebo jako hodnoty). - balík (package) – určen pro modularizaci meta-modelů. Zpravidla totožný s MOF meta-modelem. - omezení (constraint) – třída, asociace a typ dat utváří jednoduchý model pro meta-data. Umožňuje omezit meta-data, aby byla dobře formulovaná či sémanticky smysluplná. 2.1.6 NIAM (Nijssen’s Information Analysis Methodology)NIAM byl původně navržen pro informační analýzu, ale později se použil v několika meta-modelovacích technikách. Základní prvky NIAM jsou: - stav (state) - přechod (transition) - třída (class) - atribut (attribute) - operace (operation) Je vhodný pro tvorbu stavového modelu.
Obrázek 6 Meta-model stavového modelu pomocí NIAM [3] 2.2 Architektura aplikaceCílem této kapitoly není určit architekturu výsledné aplikace, ale spíše naznačit, z jakých je možné vybírat. Nejdůležitější je určit, jaký druh softwaru je vyvíjen. Protože výsledným produktem bude možné vytvořit CASE nástroj, je otázkou, jakým způsobem bude použitelný. Většina meta-CASE nástrojů rozšiřují spolu s novými CASE nástroji svou nabídku a tím nabízí uživateli větší doménu modelů. To by pochopitelně měla zahrnovat i výsledná aplikace. Existuje však i jiný pohled. Aplikace by mohla uživateli nabídnout vytvoření nového CASE nástroje . Ten by poté byl výsledným projektem, který by bylo možné za pomoci frameworku spustit jako samostatný CASE nástroj. Ač se může zdát tento požadavek poněkud zbytečný, není tomu zdaleka tak. V praxi je naopak často žádáno, aby úpravy na vyšší úrovni uskutečňovala jen malá skupina vývojářů a ostatní mohli CASE nástroj pouze používat. K tomuto účelu je daný framework, protože neumožňuje úpravu, ale pouze používání onoho CASE nástroje. Tento koncept do jisté míry vede k alespoň částečné modularitě architektury. Není sice nutné navrhovat architekturu jako modulární, ale měla by být schopná využívat pluginy, resp. přídavné knihovny. Monolitická architektura je možná také. Ta však zřejmě bude mít nevýhodu ve dvojité kompilaci a komplikovanějším vytváření dedikovaného CASE nástroje. Jiný způsob implementace by nabízela architektura server-klient. Server jakožto jádro aplikace by nabízel všechny funkce od používání CASE nástrojů přes jejich správu a úpravu po vytváření nových modelů. Klient by mohl určovat, jaké volby aplikace budou aktivní, tzn., co uživatel bude moci používat (zda bude aplikace spuštěna jako meta-CASE nebo CASE nástroj). Implementace musí být robustní a vhodná pro vytváření celé řady nástrojů. Musí být schopna zahrnovat i různé domény vývoje. To vyvolává požadavek na bázi metod připravených pro vývojáře nových CASE nástrojů. Uživatel bude jistě vytvářet nové importy a exporty. K tomuto účelu zde musí mít připravenou podporu. Přístup k tomuto problému opět není jednoznačný. Zjednodušeně lze vyjmenovat základní dva přístupy. Jednodušší z hlediska vývoje aplikace je vytvořit podporu pluginů. Každý by se zaregistroval a zobrazil jako volba v menu. Při jeho vyvolání by mu byl model zpřístupněn pomocí rozhraní a veškerou výkonnou část by převzal daný plugin. Složitější, ale zato rozvinutější formou je implementovat jistou podporu - nějaký skriptovací jazyk. Jazyk nemusí být syntakticky složitý, ale dostatečný pro procházení modelu (podpora přístupu k datům), transformaci dat (báze metod a přístup k nim), vstup a výstup (I/O funkce). Import dat je složitější, protože zahrnuje lexikální, syntaktickou a sémantickou analýzu. Ta musí být opět univerzální k široké doméně formátů. Některé importy a exporty budou shodné. Jedná se například o ukládání obrázků, tisk nebo standardizovaný formát aplikace. Ty bude možné implementovat jak pomocí pluginů, tak přímo v aplikaci. Obdobnou roli zde hrají i jiné funkcionality. Typickým příkladem jsou grafické doplňky. U většiny CASE nástrojů je vždy nabídka, kterou lze do modelu vložit text, obrazec či obrázek, který z hlediska modelu nemá žádný význam (jedná se pouze o kosmetickou úpravu modelu). Jedinými místy, kde se tyto prvky projeví, jsou import/export standardizovaného výstupu aplikace, tisk a export do obrázků. 3 Analýza a návrh řešení3.1 Struktura meta-modeluMeta-model má být schopen reprezentovat jakýkoliv model, který bude v rámci aplikace vytvářen. Proto musí odrážet reálné modely. Každý model se skládá z entit a vazeb mezi nimi. O každé součásti lze evidovat řadu vlastností (název, číslo či jinou datovou strukturu definující parametry). Řada modelů, resp. CASE nástrojů však nabízí uživateli více možností a voleb. Ty mají modeláři ušetřit práci a čas, případně zvýšit kvalitu návrhu. Vzhledem k předchozí kapitole, kde byly ukázky některých modelů, je nutné v této kapitole pouze shrnout prvky meta-modelu, které budou implementovány. Hlavním vodítkem bude koncept GOPRR, ale výsledný návrh nebude pouhou kopií, resp. nasazením. GOPRR byl zvolen, protože nejlépe vystihuje můj pohled na problematiku a vzhledem k jeho nasazení v metaEdit+, také pro jeho prověření. 3.2 Navrhované součástiGOPRR se skládá z malého množství konstruktů (viz Obrázek 5). Daná terminologie se snaží spojit hlavní součást pod pojem graph. Ten představuje model, resp. schéma. Obsahuje množiny objektů, vlastností, rolí a vztahů. Pro snadnější popsání modelu budu postupovat od zdola nahoru. - vlastnost o hodnota blíže specifikující § objekt § vztah § roli § diagram o je pevně spjatá s daným prvkem o může být § předem definovaná · každý typ objektu je nutné pojmenovat · objekty a vztahy musí definovat svou grafickou reprezentaci § volitelná · až meta-modelář bude přidávat vlastnosti na základě požadovaného modelu · je podstatná z hlediska generování exportů, vykreslování elementů a vztahů, či ke kontrole skriptovacím jazykem - objekt o představuje jakoukoliv součást, např. § entita v ER-modelu § třída v diagramu tříd o může být definovaná řadou vlastností § pevně ukotvené · druh, resp. název objektu · grafická reprezentace (je vždy vyžadována, ale vytvářená uživatelem) · lokální jméno · dědičnost (role nebo objekt) § volně dodefinované, např.: · název generované tabulky v ER-modelu · private/protected/public u diagramu tříd · popis - vztah o jedná se o jakoukoliv relaci mezi n-ticí resp. dvojicí objektů o vlastnosti definují § možné objekty, se kterými ji lze použít (napojitelnost) § grafickou reprezentaci § uživatelem definované vlastnosti popisující typ vztahu - role o role je prvek slučující vlastnosti objektů. Každý objekt, který má nějakou roli, přebírá její vlastnosti. § lze definovat možný vztah role-objekt a pouhým přidáním objektu do role, rozšířit možnosti objektu. § představuje polymorfismus při návrhu - graf o představuje kompletní návrh modelu o skládá se z použitých § rolí § objektů § vztahů § vlastností o definuje možné propojení elementů o může mít své vlastnosti, např.: § popis § autor § DPI Objekt a role se mohou vyskytovat samostatně v nějakém repositáři a případně je lze využívat ve více modelech. Modelář poté nemusí shodné objekty vytvářet pro různé modely znovu, což může do jisté míry zrychlit vývoj. Naopak vlastnost, relace a diagram nemohou, protože: - vlastnost je vždy pevně spjatá z nějakým prvkem (grafem, objektem, rolí nebo vztahem) - relace je určena s konkrétními objekty (v určitém grafu), se kterými se pojí - graf představuje konkrétní model a proto není možné ho při vývoji znovu používat
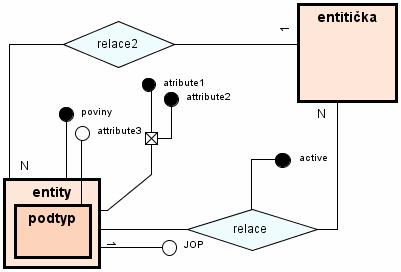
Obrázek 7 Vztah role, vztahu, objektu a vlastnosti Diagram (Obrázek 7) zobrazuje možnou reprezentaci modelu. Graph obsahuje 4 druhy prvků (role, objekt, vlastnost a vztah). Role může dědit pouze jinou roli a tím přebírat její vlastnosti. Objekt může vzniknout jak děděním rolí tak i objektů. Obsahuje grafickou reprezentaci a řadu vlastností. Vztah je připuštěn pouze binární. V konečném důsledku může být spojen pouze s objekty. Při návrhu je však možné definovat spoj i s rolí. Díky tomu bude spoj možný se všemi potomky. Takový model je zobecněním všech modelů, která obsahující objekty a binární vazby, včetně těch, která lze na ně zjednodušit (např. rozdělením n-árního vztahu na binární). 3.2.1 Struktura modelu a meta-modeluModel a meta-model budou obsahovat podobné součásti. Bude zde vždy existovat dvojice meta-model – model (definice – instance). To do jisté míry odpovídá objektovému návrhu ve vyšších programovacích jazycích založených na virtuálním stroji (Java, SmallTalk aj.). Např. v meta-modelu bude objekt MetaGraph, reprezentující nějaký konkrétní meta-model a pro modely bude N instancí objektu Graph. Ty budou pevně spojeny s konkrétním objektem MetaGraph a budou představovat konkrétní diagram (schéma). Pro snadnější práci s modelem resp. meta-modelem zde přibudou dvě dvojice tříd, které nemají s modelem ze sémantického hlediska nic společného: - Object (MetaObject) o Reprezentuje jakoukoliv třídu v modelu (meta-modelu) o Zobecněná součást o Nabízí práci se názvy - WithProperty (MetaWithProperty) o Představuje podskupinu tříd modelu (meta-modelu), které mohou mít definované vlastnosti (diagram, objekt, vztah nebo role) o Spravuje vlastnosti (přidávání, odebírání a jejich úpravu) Zavedení třídy Object představuje zároveň terminologický spor. Object jako základní třída modelu nebo jako prvek modelu. Proto se budu od tohoto místa o objektu reprezentující prvek modelu vyjadřovat jako o elementu. Object resp. MetaObject bude zahrnovat všechny společné části. Jedná se o podporu pro generování nových názvů a jejich úpravu. Na této úrovni se nejedná o vlastnost. Ta je vygenerována na základě názvu až v objektu WithProperty, resp. MetaWithProperty. WithProperty resp. MetaWithProperty bude zobecněná třída pro graf, vztah, element a roli. Její zavedení umožňuje snadnější práci se všemi součástmi obsahující vlastnosti. 3.2.2 VlastnostVlastnost představuje základní část, která může být vlastně spojena s jakoukoliv jinou částí, tzn. s: - rolí - elementem - vztahem - grafem Její využití bude v aplikaci klíčové. Všechny ostatní prvky modelů budou pomocí vlastností definovány. Vlastnost bude představovat veškerá možná data zadaná uživatelem: - jméno objektu (mimo vlastnosti samotné) - vzhled (elementu a vztahu) - pozici a velikost - data, která reprezentuje element nebo vztah - dědičnost (role, element) - připojitelnost (konce vztahů) - uživatelská data a jiné Vzhled bude realizován tak, že bude v rámci aplikace pouze jedna instance vzhledu. Před vykreslením budou nastaveny parametry (vlastnosti) a vykreslen náhled. To vyvolává otázku, jakým způsobem bude měněna hodnota textů v textových polích, či jak bude možné ovlivnit vzhled na základě vlastností. Zde na řadu přichází skript. Skript bude možné spustit před každým čtením vlastnosti, tzn. i před vykreslením, a nastaví správnou hodnotu. Proto meta-vlastnost nebude zahrnovat pouze název a typ, ale i skripty vyvolávané událostmi (po inicializaci, před čtením a po zápisu). Typ dat je obecně možné zadat buď pomocí předpisu, který poté vygeneruje danou vlastnost, nebo tak, že meta-vlastnost bude obsahovat již vytvořený datový typ a ten se bude kopírovat. Druhá varianta je jednodušší a přináší i možnost přednastavené hodnoty. Proto bude pro implementaci využito kopírování přednastavené hodnoty. Data mohou nabývat celou škálu datových typů: - celočíselná hodnota - číslo s plovoucí čárkou - hodnota boolean - řetězec - vektor (seznam) hodnot - záznam (několik dvojic název-hodnota) - součást modelu nebo jeho instanci - objekt vytvořený skriptem 3.2.3 ElementElement z hlediska modelu představuje několik vlastností, kterými je definován: - dědičnost (element nebo role) - vzhled - název - uživatelem definované hodnoty popisující jeho význam Tyto vlastnosti jsou definovány na úrovni meta-modelu. Při vytváření instance elementu budou vytvářet pouze instance meta-vlastností definovaných uživatelem a ostatní budou společné pro všechny instance, tzn., že stačí v elementu udržovat ukazatel na meta-element. Element by měl nabízet metody pro zjištění dědičnosti (metoda instanceOf určí jestli MetaObject je předchůdcem nebo ne) a metody getter-setter pro získání základních vlastností (napojitelnost, dědičnost, vzhled aj.). Ostatní podpora elementu bude implementována v jiných částech kódu (mimo model resp. meta-model). 3.2.4 VztahVztah je objekt, určený spojením dvojic element-element, element-role nebo role-role. Výsledné spojení ve schématu je možné pro jakoukoliv dvojici elementů, které jsou potomky objektů, pro které je definováno napojení. Vztah je z grafického hlediska složen z dvou polovin. Tyto poloviny jsou odděleny středem. Ten bude realizován za pomoci drageru (úchytu). Každá z polovin se skládá z čáry (spojnice) a zakončení. Pro zakončení je podobný grafický návrh jako pro element. Spojnice jsou učeny na základě barvy, tloušťky a stylu čáry (plná, přerušovaná aj.) Obě zakončení a spojnice tvoří vzhled vztahu. Dvě datové struktury omezují možnosti napojení pro každý konec zvlášť a další dvě vlastnosti určují způsob napojení (na střed, k obvodu obdélníků příp. jiné). Vztah z hlediska modelování může být často n-ární, např. v ER-modelu.
Obrázek 8 Ukázka základních konstrukcí ER-modelu Zjednodušení vztahů pouze na binární však neznamená, že by takový vztah nešel v plánované aplikaci vytvořit a má navíc i další výhody. Obecně nelze popsat všechny možné vztahy, protože mohou být rozmanitější, a z hlediska návrhu meta-CASE nástroje není možné dopředu omezit množství zakončení či složitějších grafický prvků, které obsahuje. Je ale možné takový vztah rozložit na elementy a řadu binárních vztahů. Příklad (viz Obrázek 8) by se tedy rozložil na 2 druhy elementů: - Entita (viz entity1, entity2, entity3 nebo subentity3) - Vztah (viz relationship) Jeden typ vztahu spojuje oba druhy elementů. Toto omezení stačí k tomu, aby nešlo přímo spojovat elementy relací nebo entit. Obdobným způsobem lze realizovat atributy. Atribut i klíč jsou elementy. K jejich propojení jsou určeny jiné binární vztahy. Proto se takováto změna neprojeví zhoršením návrhu. Ten bude pouze o něco složitější při vytváření exportů (skript bude muset procházet model do větší hloubky). 3.2.5 RoleRole je specifická součást. Ta má obdobné vlastnosti jako Element. Rozdíl mezi rolí a elementem je pouze v tom, že role nemůže vzniknout děděním elementu a nemá grafickou reprezentaci. 3.2.6 DiagramDiagram je objekt, který zahrnuje
všechny použité elementy, role, vztahy včetně jejich vlastností. Diagram
obsahuje i své vlastnosti. Některé z nich budou povinné: -
autor -
název - popis - DPI (rozlišení, v kterém je schéma vytvářeno – má vliv pouze na tisk)
Obrázek 9 diagram tříd modelu a meta-modelu 3.3 Architektura aplikaceArchitektura aplikace vychází z dříve zmiňovaných předpokladů (viz 2.2). Musí být navržena pro podporu: - importu - exportu Výhodou aplikace by byla podpora pluginů. Import, export a případné pluginy budou používány pouze za pomoci skriptu. Nebude tedy možné např. vložit plugin, resp. načíst třídu mimo skript (např. jako vzhled). Použít modulární architekturu je vzhledem k očekávanému dělení příliš náročné, protože součásti, které budou použity pouze v meta-CASE, se týkají úpravy meta-modelu. To zahrnuje pouze náhledy na meta-model, ale meta-model sám o sobě nikoliv. Části pro editaci vzhledu, vlastností, skriptu a další části budou pro CASE a meta-CASE nástroj společné (záleží na způsobu užití komponent). Díky tomu je těžké vyčlenit součásti, a tak rozdělení bude realizováno dvěma různými sestaveními, která se budou lišit v množství přídavných knihoven. Tyto knihovny budou obsahovat i upravené třídy, např. uvítací stránka nebude obsahovat volbu vytvořit CASE. 3.3.1 Potřebné součástiAplikace se skládá z několika částí. Základním blokem je meta-model, resp. model (viz 3.1, Obrázek 9). S modelem blízce souvisí třídy určené pro ukládání a načítání modelu, resp. meta-modelu. Pro úpravu a vytváření modelů je dále součástí grafická reprezentace modelu, resp. meta-modelu. S tímto blokem blízce souvisí GUI, zahrnující všechny dedikované prvky uživatelského rozhraní. Pro plnou funkci modelů je určena komponenta skriptu. Skript se dále člení do lexikální a sémantické analýzy. Na sémantickou analýzu blízce navazuje interpret a předdefinované funkce a objekty. Všechny součásti jsou ale velmi svázány: - grafická reprezentace modelu s modelem samotným - skript s meta-vlastnostmi, resp. vlastnostmi - meta-model s modelem - aplikační část komponent pro práci s grafickou reprezentací a meta-modelem, resp. modelem - grafická reprezentace se skriptem Je proto těžké rozdělit projekt do samostatných částí, kdyby byla zvlášť grafická reprezentace, model, skript, GUI a další součásti. V řadě případů by se jednalo spíše o zbytečnou komplikaci. Vůči návrhu MVC (model-view-controller) je samozřejmě vhodné oddělit grafickou část od modelu. V implementaci budou použity anonymní třídy, které budou složité (vyčleněné) komponenty rozšiřovat pro specifický účel. Nebude se jednat o kroky proti MVC, ačkoliv přístup ke grafickým komponentám, které jsou přímo spjaty s modelem, budou inicializovány v třídách modelu. Je vhodné, aby tyto třídy udržovali jednu instanci i v momentě, kdy komponenta není používaná a nedocházelo tak ke ztrátě informací (např. rozvržení elementů a vztahů v diagramu). Pro znázornění plánované aplikace, resp. součástí aplikace a jejich návaznosti dostatečně poslouží konceptuální model (Obrázek 10). Konceptuální model nepředstavuje žádný formalizovaný model, ale je dostatečně ilustrativní. Na modelu jsou jasně vyznačeny všechny součásti návrhu a jejich vzájemná spojitost a obsáhlost. Zároveň je zde naznačena oblast potřebná jak pro meta-CASE, tak i pro dedikovaný CASE nástroj. Je zněj poměrně zřejmě vidět, že pro rozdělení na dvě aplikace modularita nijak významně nepomůže a proč je nutné vytvořit dvě různá sestavení.
Obrázek 10 Konceptuální model navrhované aplikace 3.3.2 FrameworkFramework bude část aplikace určená pro uložení všech aditivních i základních funkcí pro chod aplikace. Ve výsledné aplikaci bude framework představovat prakticky veškeré funkce a podpory. Mimo něj bude součástí aplikace pouze model včetně jeho správy, spouštěcí třídy a použité knihovny. Jeho vyčlenění bude značně odlišné od konceptuálního modelu, který se snažil naznačit spojitosti a co nejvíce rozčlenit návrh pro představu o součástech. Jak již bylo řečeno dříve (viz 3.3.1) veškeré celky frameworku jsou na sobě více, či méně závislé, není tedy možné využívat model bez meta-modelu samostatně, grafickou reprezentaci bez skriptu, apod. 3.3.2.1 GUISoučást frameworku bude balík GUI. Jedná se o repositář všech použitých komponent vyvinutých pro aplikaci: - editor (EditorPane) o bude pracovat s grafickým návrhem, náhledem i se samotným modelem (schématem) - náhled tisku (PrintPreview) - pracovní okna o jedná se o dokovací okna, reprezentují jiné informace o upravovaném modelu, resp. meta-modelu § průzkumník vlastností § průzkumník meta-vlastností § průzkumník modelu § okna pro návrh vzhledu § konzole - nástrojové lišty o standardní (uložit, načíst a další) o výběr fontu o grafické prvky o přiblížení o interpret - dialog pro volbu souboru o vznikne rozšířením JFileChooser - uvítací stránka a její součásti - roletové menu o obsahující položky menu, včetně jejich spravování - renderery a editory hodnot vlastností pomocí JTable - dialogové okno pro změnu hodnoty vlastnosti - dialogové okno pro nastavení typu dat - podpora pro práci s kontextovými menu - náhledy meta-modelu a meta-vztahu 3.3.2.2 Součást skriptovací jazykTato součást bude zahrnovat celý skriptovací jazyk včetně editoru. Skriptovací jazyk bude jednoduchý – podmnožina JavaScript. JavaScript je jazyk vycházející z Javy. Jeho základní konstrukty jsou jednoduché, blízké jazyku C++ a celosvětově známé. JavaScript sice nenabízí složitější konstrukce, ale ty také nebudou vyžadovány. Nejsložitější částí zde bude jistě přístup k datům a zápis do souboru. Ať by byl použit jakýkoliv skriptovací jazyk, bylo by nutné pro I/O funkce vytvořit knihovny, a proto rozšíření o vlastní metody není považováno za komplikaci. JavaScript má řadu výhod pro aplikaci. Není nutné deklarovat typy a provádět typovou kontrolu. U objektu se dají používat nedefinované proměnné, což může značně pomáhat při vytváření importu a exportu. Například při procházení modelu prohledáváním do šířky je možné u každého elementu evidovat proměnné určující stav prohledávání, aniž by bylo nutné dopředu (mimo skript) proměnné explicitně definovat. Tento skriptovací jazyk zároveň přináší výborné vlastnosti z pohledu překonávání chyb. 3.3.3 Vzhled aplikaceAplikace bude mít jednoduché GUI ve stylu klasických CASE nástrojů. Bude se jednat o SDI (Single Dialog Interface). Více otevřených dokumentů bude možné přepínat pomocí záložek na horní straně okna (obdobně jako u vývojových prostředí). Grafický návrh se vlastně týká úvodní stránky. Vzhled celé aplikace bude rozšířen o roletové menu, panely nástrojů a pracovní okna. Ty budou volitelné a posouvatelné díky dokování resp. knihovně FlexDock.
Obrázek 11 Navrhovaný vzhled (rozvržení úvodní obrazovky meta-CASE nástroje) 3.4 Detailnější popis součástí3.4.1 Grafický editorGrafický editor bude reprezentován třídou EditorPane. Pomocí ní bude návrhář definovat elementy, prohlížet si náhledy i vytvářet schémata. 3.4.1.1 Návrh vzhleduVzhled může být definován pro element, nebo zakončení vztahu. Pro návrh vzhledu budou použity základní grafické prvky (čára, obdélní, polygon, textové pole a další), dále jen dekorace. Dekorace je možné používat, jak pro návrh vzhledu, tak i jako doplněk do vzniklého schématu. Každá dekorace je vykreslena na základě vlastností, jakými jsou například tloušťka a typ čáry, barva a jiné. Hlavními vlastnostmi jsou body, na základě kterých je určen rozměr a pozice dekorace. Protože všechny elementy mohou být „roztahovací“, musí návrh respektovat změny velikosti. Každý bod musí být možné specifikovat relativně. Cílem je umožnit maximum volnosti a jednoduchost návrhu. Výhodou je, že takový návrh bude proveden pouze jednou (při vytváření CASE) a poté jen používán. Proto bude použita lokalizace 2 typů: 1. relativní souřadnice, např.: · 5px od levého okraje (obálky) · 0px od pravého 2. relativní pozice, např.: · 20% horizontálně (od levého okraje) · 0% vertikálně (od horního okraje) Tím je možné jak rozdělit plochu na 2 části v určitém poměru, tak i vložit detail k nějakému z rohů. Obdobný způsob využívá SmallTalk při návrhu GUI. Návrh je tak zproštěn o layout managery a přesto je dynamický. Druhá část návrhu je složitější. Jedná se o vložení textových polí. Textové pole může obsahovat různě velký text. Problém nespočívá v umístění jednoho textového pole. To se dá snadno vyřešit pomocí roztáhnutí elementu. Problém přichází až u návrhů, které obsahují více těchto textových polí. Dopředu není jasné, kolik řádek bude každé textové pole obsahovat, resp. jak dlouhé bude mít řádky. Typickým příkladem pro tuto problematiku je vzhled třídy v UML. Obsahuje 3 různá textová pole, přičemž minimálně u dvou nejsou dopředu jasné rozměry a je nutné použít složitější techniku k definici.
Obrázek 12 Třída v UML Výše zmíněný návrh vzhledu pracuje pouze s jediným panelem (plátno ve tvaru obdélníku). Problém je řešen rozdělováním panelu. Každý panel bude možné rozdělit vertikálně, resp. horizontálně na dva potomky. Tím vzniká binární strom panelů. Na úrovni každého z nich je možné přidávat dekorace. Rozměry všech potomků jsou určeny na základě preferovaných velikostí, tzn., že pro každý z panelů se vypočítá hodnota preferované velikosti a velikost hlavního panelu (který je členěn) se rozdělí v poměru preferovaných velikostí potomků. Třída by se vytvářela např. tímto způsobem (relativní adresy jsou vůči levému hornímu rohu): 1. hlavní panel se rozdělí horizontálně 2. horní z panelů se opět rozdělí horizontálně 3. do hlavního panelu se vloží bílý plný obdélník ([0%,0%]-[100%,100%]) 4. do hlavního panelu se vloží černý obdélník ([0%,0%]-[100%,100%]) 5. do spodních 2 nerozdělených panelů se vloží černá čára na horní hranu ([0%,0%]-[100%,0%]) 6. do každého nerozděleného (listového) panelu se vloží textové pole ([5%,5%]-[95%,95%]) 7. pro každé pole se vytvoří metoda, která vrátí text, např.: · getName() // vrátí řetězec vlastnosti název · getAttributes() // vrátí řetězec s názvy atributů oddělených \n · getOperations() // vrátí řetězec s názvy operací oddělených \n 8. propojí se patřičná textová pole s metodami
Obrázek 13 Znázornění příkladu použití panelů (element třídy v UML) Jiný pohled je možné ukázat na struktuře. Panel může mít definovány 2 potomky, resp. buď žádné, nebo právě dva. Způsob rozdělení (horizontální nebo vertikální) a dále seznam dekorací. Každá dekorace poté zahrnuje několik vlastností, kterými je deklarována.
Obrázek 14 Ukázka struktury grafické reprezentace (vlastnost vzhledu) 3.4.1.2 ModelContainerTřída ModelContainer bude představovat prvky, se kterými editor pracuje. Bude umožňovat přidávání a odstraňování prvků. Dále se bude starat o jejich seřazení podle vrstvy a pomocí jejich metod bude možné získat seznam prvků pro vykreslení nebo pro výběr. Děděním vzniknou dvě varianty: - Panel (pro návrh vzhledu) - Diagram (pro náhledy a práci s modelem) 3.4.1.3 EditorPaneEditorPane je komponenta, která využívá ModelContainer. Zprostředkovává vykreslování, přidávání prvků, jejich úpravu (posun, změna velikosti) a tisk. Mezi základní operace patří změna velikosti pracovní plochy, přiblížení, resp. oddálení a vyvolávání kontextových menu u zobrazovaných prvků. Dále umožňuje pracovat se vztahy (napojování a odpojování). 3.4.1.4 Náhled tiskuNáhled tisku bude realizován úpravou EditorPane. Ten mimo jiné vykresluje pracovní plochu. Přetížením metod pro přidávání a odebírání prvků vznikne komponenta bez možnosti úprav (vkládání dekorací apod.). Dále bude přetížena metoda paintComponent, určena pro vykreslení editovaných prvků. Pomocí ní bude vykreslen samotný náhled. Komponenta bude opatřena panelem nástrojů pro volbu formátu a čísla stránky. Další tlačítko panelu bude sloužit k vytisknutí dokumentu. 3.4.1.5 Dialog pro výběr souboruVýběr souboru bude možný pomocí speciálního dialogu. Ten bude využívat JFileChooser. Dialog bude nabízet možnost přidání filtru souborů. Pomocí něj bude možné odfiltrovat soubory na základě přípony. Přidání filtru bude určeno pomocí přípony, popisu filtru a případně posluchačem ActionListener. Posluchač bude vyvolán v případě, že by byl vybrán daný filtr a soubor byl zvolen. 3.4.1.6 Úvodní stránkaÚvodní stránka (viz Obrázek 11) se bude skládat z několika částí. V pravém horním rohu bude seznam až 5 posledních otevřených souborů. V levém horním rohu bude uvedeno číslo verze a logo aplikace. Spodní část bude rozdělena na dva sloupce. V levém se bude nacházet několik komponent BoxComponent (viz 3.4.1.7) pro zobrazení zajímavých informací o aplikaci. Celkem jsou plánovány tři kategorie: - novinky - tipy - zpětná vazba o hlasování o kvalitě aplikace o možnost zaslat textovou zprávu vývojáři V pravém sloupci bude dekorativní řádka s 2 volbami (přidat a vytvořit CASE nástroj). Pod ním se bude nacházet řádka umožňující filtraci výpisu meta-modelů, který se nachází pod ním. Každý záznam o meta-modelu bude obsahovat název, popis, jméno autora, datum sestavení a základní volby (vytvořit CASE, upravit meta-model). 3.4.1.7 BoxComponentJedná se o jednoduchou komponentu schopnou zobrazit několik stránek. Bude obsahovat tři tlačítka. Dvě se budou nacházet ve spodní části a budou určena k posunu v rámci stránek (předchozí a následující strana). V horní části bude titulek a tlačítko, kterým bude možné komponentu minimalizovat, resp. maximalizovat. 3.4.2 SkriptJak již bylo řečeno v kapitole 3.3.2.2 pro skriptování bude použita podmnožina jazyku JavaScript. Použití celého standardu není potřeba a ani žádoucí. Velké množství funkcí a podpory je totiž spojeno s HTML kódem a proto nepoužitelné pro potřeby aplikace. 3.4.2.1 Podporované částiImplementovány budou některé cykly (do-while, while a klasický for), výrazy, volání metody, funkce, definice proměnných, definice konstant a základy OOP. Dále je nutné implementovat základní metody a objekty např.: - Math - document.write, document.writeln - eval Prvky modelu, resp. meta-modelu bude nutné obohatit o metody, aby je bylo možné procházet a vytvářet. Dále je nutné zajistit podporu pro práci se soubory. K tomu budou určeny objekty FileWriter a FileReader. Tyto objekty nejsou součástí JavaScriptu, ani nerespektují stejnojmenné objekty v Javě. Jedná se o nestandardní objekty pro snadnou práci se soubory. Detailní popis všech předdefinovaných metod a objektů je uveden v příloze D. 3.4.2.2 GramatikaSkriptovací jazyk využívá k překladu LL(1) gramatiku uvedenou v příloze D. Pro překlad kódu bude využit rekurzivní sestup, přičemž názvy metod budou respektovat názvy pravidel. 3.5 Návrh balíčků a rozložení projektuKaždý moderní návrh aplikace využívá rozdělení aplikace do balíčků. Rozdělení respektuje blízkost tříd a umožňuje snazší přístup k jednotlivým celkům.
4 RealizacePři realizaci aplikace byl plně respektován návrh. Implementace se zaměřila pouze na meta-CASE nástroj. Možnost vytvořit derivovaný CASE nástroj nebyla implementována. Případná její realizace však představuje pouze drobné úpravy. V této kapitole budou postupně procházeny všechny balíčky (package) a popsány jejich základní třídy včetně použitých návrhových vzorů. Veškerá implementace aplikace se nachází v hlavním balíčku metacase. Ta obsahuje všechny součásti implementace aplikace. Její součástí je spustitelná třída MetaCase a dva balíčky: -
core o samotná implementace (všechny další třídy aplikace) -
res o obsahuje ikony, obrázky a textový soubor s číslem verze 4.1 Balíček metacase.coreSkládá se ze dvou balíčků: -
framework o Obsahuje GUI a další součásti mimo model a s ním přímo spojené třídy -
metamodel o Model, meta-model, typy vlastností o Ukládání a načítání XML souborů 4.2 Balíček metacase.core.frameworkFramework se rozděluje na tři, resp. čtyři základní části. Těm odpovídají i názvy balíčků: -
gui o součásti uživatelského rozhraní o vlastní komponenty o editor a jeho prvky -
script o lexikální analýza o sémantická analýza o interpret o editor kódu -
undo o správce změn o nabízí funkce zpět a vpřed -
other o nezařaditelné součásti 4.3 Balíček metacase.core.framework.gui4.3.1 Třída AboutDialogDialogové okno „o programu“. Vypíše verzi a text o programu. 4.3.2 Pracovní oknaPracovní okna jsou realizována na technologii FlexDock. Implementovány byly pouze komponenty, tvořící jejich těla. Každá taková komponenta je navržena tak, že obsahuje statickou proměnnou zahrnující všechny instance pracovního okna. Dále jsou zde statické metody refreshAll nebo resetAll. Ty obnoví stav všech instancí. Komponenta tedy představuje náhled editované části. V aplikaci je v současné době možné zobrazit každý panel maximálně jednou. Šlo by tedy použít návrhový vzor soliton. Obě varianty mají stejný způsob použití, ale použitý styl dovoluje větší rozšiřitelnost (možnost vytvoření různých variant pracovních oken zobrazovaných v jeden moment).
Tabulka 1 Pracovní okna 4.3.3 Třída JMenuBarFilledJMenuBarFilled je komponenta roletového menu. Vznikla zděděním třídy javax.swing.JMenuBar. V konstruktoru je komponenta naplněna všemi menu a volbami (viz C.5). Komponenta zahrnuje vnořenou třídu JMenuRight. Jedná se o komponentu, reprezentující prázdné místo v roletovém menu. Její rozměry jsou určeny šířkou celého menu a součtem všech nabídek. Vkládá se před poslední nabídku. Díky tomu se poslední menu zarovná doprava. 4.3.4 MenuContainer, MenuContainerInterface a MenuContainerDynamicAplikace obsahuje spoustu komponent, které mají vlastní kontextové menu. Pro snadnou správu vzniklo několik tříd a rozhraní. MenuContainerInterface je rozhraní, které dědí všechny komponenty obsahující kontextové menu (součásti modelu i GUI). Nabízí dvě metody, které vrací objekt typu MenuContainer pro komponentu, resp. pro pozici v ní. To se využívá například u editoru. Zde jsou zobrazeny grafické reprezentace modelu a editor vypočítává, kterého prvku se akce týká. MenuContainer je třída, do které se snadno přidávají nové volby. Každá volba může být zadána několika řetězci.
Tabulka 2 Parametry MenuContainer typu String Volba může být obohacena o ikonu (ImageIcon) nebo akci, která se provede při vyvolání (ActionListener). Zadání položky může být realizováno i za použití standardních objektů typu JMenu, JMenuItem nebo jejich potomky. Objekt MenuContainer vytvoří kontextové menu, vrátí ho a nakonec se vyhodnotí funkce, zda byla provedena správná akce (pravé tlačítko myši nebo klávesa pro vyvolání kontextového menu) pro vyvolání menu a případně ho zobrazí. Výše popsané prvky se vytváří pouze na úrovni implementovaného kódu. Některá menu je však možné vytvářet i na úrovni skriptu (pro rychlejší práci s vytvářeným modelem). Proto je zde k dispozici MenuContainerDynamic. Tato třída vytváří podobnou strukturu jako MenuContainer, ale za pomoci skriptu. Nabízí možnost vložit své volby do nějakého MenuContainer a tím obě kontextová menu „spojit“. Taková menu je možné vytvářet u tříd Relationship (vztah), Element (element) a End (zakončení vztahu). Při jejich volbě se provede volání metody skriptu. 4.3.5 Třída BaseViewTřída BaseView je komponenta založená na javax.swing.JTabbedPane. Je hlavní součástí aplikace. Umožňuje zobrazovat editory, úvodní stránku, náhledy meta-modelu a náhled tisku. Spravuje jejich přepínání (při přepnutí mezi záložkami obnovuje data pracovních oken), umožňuje jejich přidání a odebrání. Tato třída může být v aplikaci pouze jednu instanci a využívá návrhový vzor soliton. 4.3.6 Třída WelcomeScreenÚvodní stránka je první záložka, která se po startu aplikace zobrazí v komponentě BaseView (viz 4.3.5 a C.1). Ač může mít v celé aplikaci maximálně jednu instanci, nevyužívá návrhový vzor soliton, protože instanci vytváří pouze třída BaseView. Ta vytvoří instanci úvodní stránky na začátku a udržuje jí po celou dobu. Skládá se z řady komponent: - BoxComponent – nabídky novinky, tipy a zpětná vazba - MetaCaseList – seznam meta-modelů k práci - LastOpenedFiles – udržuje N (5) naposled otevřených souborů 4.3.7 Třída BoxComponentKomponenta umožňuje prohlížení množiny dokumentů, či komponent. Zprostředkovává jejich přepínání a zobrazování. Abstraktní třída metacase.core.framework.gui.infos.DataContainer (viz Obrázek 18) nabízí jednoduché metody pro zjištění pozice a počtu stránek. Další metody umožňují změnu pozice (vpřed a vzad) a zjištění informací o ní (možnost posunu vpřed a vzad). Děděním třídy DataContainer vznikla pro každou komponentu s informacemi zvláštní třída udržující a spravující množinu zobrazovaných stránek (třídy News, Feedback a Tips). 4.3.8 Třída PrintTřída Print představuje obsluhu tisku. Vstupem je obrázek vygenerovaný editorem. Pokud je obrázek větší než formát papíru, rozloží ho na několik stránek. Třída zprostředkovává jak samotný tisk, tak i vykreslování náhledu tisku (viz 4.3.9). 4.3.9 Třída PrintPreviewNáhled tisku je založen na dvou třídách: -
EditorPane o K zobrazení náhledu (vykreslí papír a zajistí přibližování) -
Print o Výsledný tisk o Vykreslování obsahu dokumentu 4.4 Balíček metacase.core.framework.gui.editorBalíček zahrnuje všechny použité součásti pro editor a jeho grafické reprezentace. Obsahuje další dva balíčky: -
anchor o přichycení zakončení vztahu k elementu -
decores o všechny dekorace pro práci v editoru a interface pro vkládání 4.4.1 PaintInterface, PaintLayerInterfacase a MoveableTrojice rozhraní pro práci s grafickými prvky. Rozhraní PaintInterface nabízí metodu pro vykreslení prvku do java.awt.Graphics2D. Rozhraní PaintLayerInterface ho rozšiřuje tím, že přidává metody pro změnu a zjištění vrstvy, na které se prvek nachází. Poslední rozhraní Moveable je určeno pro všechny prvky umožňující pohyb po plátně. Nabízí metody pro pohyb i metody pro zjištění, zda obsahují nějaký konkrétní bod a vzájemnou polohu dvou prvků. 4.4.2 Třída EditorPanePředstavuje editor se základními metodami pro jeho správu:
Tabulka 3 Základní metody EditorPane Editor dále spravuje události myši a klávesnice, tzn. pohyb prvky, mazání pomocí klávesy delete, označování mnoha prvků a další. 4.4.3 ModelContainer, Diagram, Panel, PanelsTreeModelContainer je abstraktní třída reprezentující obsah editovaného modelu. Používají se třídy vzniklé jeho zděděním: Diagram a Panel, resp. PanelsTree. Diagram je určen pro modely, protože zahrnuje nejen dekorace, ale i elementy a vztahy. Naproti tomu Panel se používá při vytváření vzhledu (elementu nebo zakončení vztahu). Může obsahovat pouze dekorace. Protože analýza předpokládala strukturu panelů (viz 3.4.1.1) a třída Panel představuje pouze jeden z nich, vznikla děděním třída PanelsTree. Ta nabízí stejné možnosti a navíc i dělení (včetně zobrazování potomků). 4.4.4 Inserter a zděděné třídyInserter je abstraktní třída určená pro vkládání prvků do editoru. Pro vložení je třeba definovat všechny body prvku. Inserter se vytvoří, nastaví se mu žádaný prvek. Postupně se mu pomocí metody setNext předávají definované body. Prvek se tak zpřesňuje. Pokud se vkládání nezruší získá editor prvek pomocí metody get. Třída Inserter nabízí také náhled (metoda preview), což umožňuje snadnější vkládání uživateli. Jak již bylo řečeno, jedná se pouze o abstraktní třídu. Je to z toho důvodu, že pomocí něj se vkládají dekorace, elementy i vztahy. Každý prvek se ale vkládá jiným způsobem. Pro určení elementu je třeba určit jeden bod (levý horní roh). Rozměry se vypočítají na základě preferované velikosti. Vložení vztahu vyžaduje nalezení elementů, se kterými se má spojit. Dekorace se dají z pohledu vkládání rozdělit na dvě skupiny: - s předem definovaným počtem bodů - polygony Proto vznikly děděním 4 třídy podle druhu vkládaného prvku (viz Obrázek 15):
Tabulka 4 Účel tříd dědících třídu Inserter 4.4.5 Třídy Element, Relationship, RelationshipLine a EndTřídy reprezentují grafickou reprezentaci elementů a vztahů. Jsou navrženy jako renderery, tzn., že vzhled každého z objektů je určen patřičným meta-objektem (meta-vztah nebo meta-element). Na něj má element i vztah odkaz. Element tedy před vykreslením nastaví vzhledu vlastnosti (pozice, velikost) a poté ho vykreslí. U vztahu je tento princip také využit, jen vzhledem ke struktuře vztahu složitěji. Zakončení vztahu nejprve provede rotaci (natočení zakončení) a vykreslí ho stejným způsobem jako element. Spojnice je reprezentována třídou RelationshipLine. Ta má stromovou strukturu odrážející zalamování spojnice. Každá třída Relationship, tzn., každý vztah má svou spojnici. Ta se tedy vykresluje přímo. 4.4.6 Třída RulersKaždý editor a náhled tisku může být opatřen pravítky (C.8). Třída Rulers zahrnuje trojici komponent (tlačítko pro přepnutí jednotek, horizontální a vertikální pravítka). Tlačítko je upravená komponenta javax.swing.JLabel a pravítko je realizováno jako nová komponenta, tzn. dědí javax.swing.JComponent. Pravítka mohou zobrazovat 3 jednotky (pixely, palce a centimetry). 4.5 Balíček metacase.core.framework.gui.editor.anchorObsahuje rozhraní AnchorInterface pro práci s všemi přichyceními zakončení vztahu k elementu. Umožňuje tedy nastavit obdélník elementu, ke kterému se přichytává, získat normálový vektor přichycení a bod napojení spojnice. V balíčku se dále nachází dva druhy přichycení:
Tabulka 5 Způsoby přichycení 4.6 Balíček metacase.core.framework.gui.editor.decoresObsahuje všechny použitelné dekorace a rozhraní pro jejich přidávání AddDecoreInterface. Ten dědí třídy Diagram a Panel, resp. ModelContainer (viz 4.4.3).
Tabulka 6 Dekorace Dekorace vznikly děděním abstraktní třídy Decore (viz Obrázek 17). Ta zajišťuje práci s dragery (úchyty pro změnu bodů), vykreslováním, serializaci a deserealizaci XML kódu. 4.6.1 NáhledyAplikace obsahuje řadu náhledů. Všechny jsou založeny na třídách Diagram a EditorPane. Obě jsou zděděny a přetíženy jejich metody, které umožňují strukturální změny. Blokuje se tedy mazání elementů a spojování, resp. odpojování vztahů.
Tabulka 7 Náhledy 4.7 Balíček metacase.core.framework.gui.infosBalíček obsahuje třídy pro udržování dat informačních komponent na úvodní stránce (viz C.1): - novinky - tipy - zpětná vazba Základem je abstraktní třída DataContainer. Ta spravuje index (pozici – číslo stánky). Nabízí a kontroluje posun. Aktuální stránka se vrací jako komponenta metodou getComponent. Novinky (News) a tipy (Tips) jsou třídy zobrazující HTML stránky. Liší se pouze úložištěm zpráv, proto Tips dědí News a pouze přetíží metodu getDir (vrací adresář úložiště). Naopak třída FeedBack vrací vlastní komponentu (anonymní třídu) buď pro hlasování, nebo pro zaslání zprávy. Informace se posílají pomocí http protokolu pomocí POST na webovou stránku umístěnou na http://metacase.ree-systems.cz/. Výsledek otevření PHP skriptu se zobrazí v dialogovém okně. 4.8 Balíček metacase.core.framework.gui.jtableObsahuje renderery a editory pro JTable. Jsou určeny pro data vlastností a meta-vlastností. Ty jsou využívány průzkumníky vlastností (viz C.3.4), meta-vlastností (viz C.3.5) a dialogovým oknem pro změnu hodnoty. V průzkumnících se ve stejném sloupci mohou editovat hodnoty různého typu. Proto je třeba, aby byl jeden renderer resp. editor zastupující řadu rendererů resp. editorů. Protože cílem nebylo mít jinou komponentu pro zobrazování a jinou pro editaci, byly renderery a editory spojeny. Zastřešujícím rendererem resp. editorem pro data vlastností je třída PropertyDataRendererEditor, pro meta-vlastnosti MetaPropertyRendererEditor. PropertyDataRendererEditor má pro každý typ jednu instanci konkrétního rendereru resp. editoru, a tu používá, je-li to třeba. Obsahuje i složité, tzn. zobrazované velkými komponentami. Pokud se ale mají zobrazit v JTable, použije se tzv. defaultní. Ten obsahuje popis dat a tlačítko pro vyvolání dialogového okna k úpravě hodnoty.
Tabulka 8 Renderery a editory pro PropertyData 4.9 Balíček metacase.core.framework.gui.toolbarsBalíček obsahuje všechny panely nástrojů (viz C.4). Ty jsou založeny na abstraktní třídě JToolBarUndecored. Ta vznikla zděděním javax.swing.JToolBar. Odstraňuje rám dialogového okna a nabízí metody pro snadné přidávání a vytváření tlačítek (JToogleButton a JButton). Panely jsou navrženy stejně jako pracovní okna. V aplikaci je dovolena maximálně jedna instance každého z panelů. Každý panel je však navržen robustně a tedy pro více instancí. Obsahují statické metody pro správu všech instancí najednou. To nabízí možnost rozšiřitelnosti u budoucích verzí (dovolí to různé varianty stejného typu panelu).
Tabulka 9 Panely nástrojů 4.10Balíček metacase.core.framework.scriptZahrnuje všechny součásti skriptu: - definici lexikálních elementů - lexikální analýzu - sémantickou analýzu - základní funkce, operace a objekty - interpret - editor kódu - proměnné (definice, funkce) - výjimky překladu 4.11Balíček metacase.core.framework.script.editorObsahuje editor kódu. Ten se rozděluje do čtyř tříd: -
JavaScriptContext -
JavaScriptDocument -
JavaScriptEditor -
JavaScriptEditorKit Ty nejen definují nový dokument (pro kód JavaScriptu) ale i EditorKit pro práci a především zobrazení kódu. Kód je obarvován po každé změně. K tomu je třeba aplikovat lexikální analyzátor. Ten vytvoří seznam lexikálních elementů (tokenů). Každý patří do nějaké skupiny a podle toho je u něj definován styl fontu a barva. Pokud je lexikální analýza úspěšná, je spuštěn i sémantický překlad. Ten vytvoří strukturu vhodnou pro interpretaci. Pokud dojde při překladu k chybě, je označen token, který nebyl očekáván (přijat) a při překreslení editoru je zvýrazněn. Zároveň se vypíše hláška o chybě do konzole. 4.12Balíček metacase.core.framework.script.exceptionsNachází se zde řada výjimek určených pro řízení běhu skriptu, interpretaci příkazů a jako výjimky překladu.
Tabulka 10 Výjimky používané pro skriptování 4.13Balíček metacase.core.framework.script.functionsObsahuje všechny základní operace a příkazy pro interpretaci skriptu, tzn. např. +, -, *=, return a další. 4.14Balíček metacase.core.framework.script.ioBalíček obsahuje pouze dvě třídy: -
BackupInputStream o Udržuje N posledních hodnot a dovoluje se vrátit zpět o Využívá se při lexikální analýze -
TextInputStream o Vytváří vstupní proud z řetězce o Využívá se při lexikální analýze 4.15Balíček
metacase.core.framework.script.tokens
Obsahuje třídy všech tokenů (pro každý token je zvláštní třída). Třídy vytváří hierarchii (dělí se na druhy tokenů). Každý druh určuje styl a barvu fontu (viz Obrázek 16). 4.16Balíček metacase.core.framework.script.variableObsahuje datové typy skriptu. Všechny jsou odvozeny od abstraktní třídy Variable. Ta dovoluje převod na jiný datový typ (konverze mezi řetězci, čísly a pravdivostní hodnotou). Pro vytváření objektů se Variable používá také, ale jako anonymní třída v reprezentovaném objektu.
Tabulka 11 Datové typy 4.16.1 Třída LexicalAnalyzerProvádí lexikální analýzu. Data pro překlad musí být typu InputStream (viz 4.21). Výstupem je seznam tokenů přístupné přes metodu get(i), případně za pomoci getIndex(i) určující index na základě pozice v kódu. Pro čtení sémantickým analyzátorem se používá vnořená třída SemanticAnalyzer.LexicalAnalyzerFilter. 4.16.2 Třída SemanticAnalyzerProvádí sémantickou analýzu. Vstupem je LexicalAnalyzer, který je proudově čten za pomoci SemanticAnalyzer.LexicalAnalyzerFilter. Za použití LL(1) gramatiky (viz 3.4.2.2) vytvoří stromovou strukturu pro interpretaci. Obsahuje několik metod, které se používají až po překladu:
Tabulka 12 Důležité metody třídy SemanticAnalyzer 4.16.3 Třída PredefinedCodeVygeneruje použitelné funkce a objekty skriptu. Jedná se o metody parseInt, parseFloat, isNaN, isFinite, alert, prompt, confirm, createGraph a objekty Date, Math, Array, FileReader, FileWriter a document. 4.17Balíček metacase.core.framework.undoTřídy určené pro ovládání funkcí zpět a vpřed. Hlavní součástí je třída UndoManager. Ta udržuje změny všech PropertyData (hodnot vlastností) a na základě nich provádí změny vpřed a vzad. Protože existují operace, které nejsou reprezentovány pouze změnou hodnoty PropertyData (posun prvku, přidání resp. odebrání prvku) obsahuje balíček třídu MoveableAsPropertyData. Ta reprezentuje pohyb prvků jako PropertyData. Přidávání a odebírání prvků je reprezentováno vnitřní třídou UndoManager.ChageRemove resp. UndoManager.ChangeAdd. UndoManager je určen výhradně pro práci s PropertyData. To ale neumožňuje používat zpět resp. vpřed v editoru kódu. Pro tuto funkci je určena třída TextEditorUndoManager vzniklá zděděním třídy UndoManager. 4.18Balíček metacase.core.framework.otherObsahuje pět nezařaditelných tříd a rozhraní, tzn. třídy použitelné z různých částí.
Tabulka 13 Třídy balíčku metacase.core.framework.other 4.19Balíček metacase.core.metamodelObsahuje třídy reprezentující modely, meta-modely a balíčky pro práci s nimi. 4.20Balíček metacase.core.metamodel.exceptionObsahuje pouze jedinou výjimku: UnsupportedObjectException. Ta se používá u polymorfních metod modelu a meta-modelu, pokud byl zadán parametr nepodporovaného typu. 4.21Balíček metacase.core.metamodel.ioNachází se zde rozhraní Loader, kterého se týká veškerá serializace a deserializace XML kódu. Nabízí metody pro snadné načítání XML. Zároveň všechny objekty, které ho dědí, generují metodou toString XML kód. Třídy ModelLoader resp. ModelSaver slouží pro načítání resp. ukládání všech potomků Loader. Proto pracuje nejen s modely a meta-modely, ale i se strukturami reprezentující poslední otevřené soubory, rozložení panelů nástrojů a vzhled. 4.22Balíček metacase.core.metamodel.propertydataNacházejí se zde veškeré typy dat vlastností a rozhraní pro odchyt událostí (po inicializaci, před čtením a po zápisu) CheckPropertyDataListener. Základní abstraktní třída PropertyData nabízí registraci posluchačů a všechny zděděné třídy pouze volají její metody pro vyvolání událostí. Ty se využívají pro spouštění skriptů definovaných u meta-vlastností a detekci změny u složitějších datových typů. Ty poslouchají změny u hodnot, ze kterých je složen (RecordBox, VectorBox a další).
Tabulka 14 Datové typy - PropertyData 4.23Balíček metacase.core.metamodel.otherObsahuje rozhraní NameInterface umožňující práci s názvem objektu (modelu a meta-modelu) a třídu Sorter. Ta seřadí množinu objektů, které dědí NameInterface podle názvu a vrátí ji v seznamu. 5 TestováníTestování aplikace mělo 2 hlavní fáze. 1. fáze se konala již během psaní aplikace, jednalo se o průběžné testování každé z komponent (např. jednotkový test) a další probíhala po dokončení aplikace jako celku. 5.1 Jednotkový testTest byl prováděn po dokončení každého z celků. Součástí tohoto testování byla i kontrola funkčnosti GUI, zda je správně zobrazováno, jestli reaguje na všechny možné vstupy, jak má, zda není jejich funkčnost omezena vlivem jiných objektů. Jednotkové testy byly největším zdrojem chyb, protože se jednalo zpravidla o první spuštění a používání jednotlivých komponent. Každá komponenta byla podrobena kontrole všech možných užití i všech variant. Tím se získala poměrně stabilní součást. Dalším krokem u složitějších komponent bylo využití těchto jednodušších komponent díky jejich sloučení. Pro takové komponenty byl opět proveden kognitivní test. Tyto další testy již odhalovaly jen minimum chyb z jednodušších komponent, ale i tak se bral zřetel na jejich funkčnost. 5.2 Integrační testováníIntegrační testy ve své podstatě provázely také celý vývoj aplikace. Jednalo se o testy, které následovaly po vložení celé nové funkcionality do aplikace. Jejich test spočíval především v odhalování případných chyb závislých na okolních částech. Tyto testy odhalovaly chyby především ze začátku, kdy framework neobsahoval skript a často chyběly i jiné celky, bez kterých nešlo z uživatelského hlediska danou část plně používat a tudíž ani otestovat. Jednalo se například o nemožnost zprovoznit diagram tříd (pro zobrazování textů je nutný skript a nastavení typu dat vlastnosti). 5.3 Regresivní testováníPomocí testů tohoto typu se má odhalit chyba, která se vyskytla jako vedlejší efekt při úpravě jiné součásti. Jedná se o velmi těžce odhalitelné chyby, protože se často na ně přijde až při dalších testech. Toto testování znamenalo především kontrolovat komponenty používající jiné, které se právě upravovaly. Těmto chybám se snažila předcházet již analýza aplikace, kdy nejen definovala jednotlivé součásti, ale určila postup vývoje, který stále rozšiřoval kód, aniž by bylo třeba se vracet zpět (metoda „olejové skvrny“). Přesto tyto testy pomohly během vývoje odstranit několik chyb. Nejpodstatnější chyba se objevila v náhledu meta-modelu, kdy se po změně funkce textového pole přestaly vypisovat texty ukázkových elementů. 5.4 Validační testováníValidační testování mělo především za úkol ověřit, zda aplikace obsahuje vše, co bylo vyžadováno. Tyto testy byly zahájeny zároveň s dokončováním aplikace. Skládaly se z postupného používání všech možných předpokládaných modelů přístupů. Vždy byl simulován některý z možných uživatelů (modelář a meta-modelář) a jeho možné ovládání aplikace, které bude takový uživatel provádět. Jednalo se tedy o kognitivní průchod po dokončení všech plánovaných částí aplikace. Výsledkem těchto testů byla kontrola všech komponent z pohledu uživatele, zda se chovají a nabízejí, co mají. Při těchto testech byly odhaleny detailní nedostatky: - Absence načítání a ukládání vzhledů - Pamatování si stavu stromu v průzkumnících 5.5 Useability testováníVeškerá zmíněná testování byla prováděna pouze formou simulace, a tedy nemusí plně vystihovat skutečné potřeby uživatele. Proto by bylo vhodné použít useability testování na skutečných uživatelích. Pro nedostatek času nebylo možné tyto testy uskutečnit. 6 ZávěrCílem práce bylo vytvořit pilotní implementaci meta-CASE nástroje, který by dovolil modelovat různá schémata. Pro ukládání dat byl vytvořen model inspirovaný konceptem GOPRR. Vzniklá aplikace dovoluje editovat libovolné vzhledy a binární vztahy. V rámci meta-modelu je možné nadefinovat omezující podmínky pro napojení. Většina funkční částí je však převedena na skript. Skript umožňuje jak měnit vzhled elementů, tak i vytvářet importy a exporty. To dovoluje modeláři značně zvýšit návrh od pouhého nakreslení schématu. Pomocí aplikace je možné vytvořit řadu CASE nástrojů a doplnit je i o funkční části. Aplikace obsahuje několik ukázek a jeden hotový CASE nástroj. Jedná se o ER schéma včetně exportu inicializačního skriptu databáze. Výsledná aplikace sice neodpovídá komerčnímu trhu, ale nabízí všechny důležité součásti pro návrh. Případné navazující diplomové práce by mohly uživatelnost a součásti upravit pro širokou škálu uživatelů. Jedná se spíše o zjednodušení složitějších akcí uživatele zavedením průvodců, spojením vkládání více prvků pomocí maker apod. Diplomová práce splnila zadání a v některých částech ho i doplnila a rozšířila. Vznikla pilotní implementace vhodná pro další rozvoj, jak na úrovni meta-modelů, tak i součástí aplikace. 7 Seznam literatury
CAME (Computer-aided Method Engineering) CASE (Computer-aided software
engineering) COMMA (Common Object Methodology
Metamodel Architecture) GOPRR (Graph-Object-Property-Role-Relationship) GUI (Graphics User Interface) MDA (Model Driven Architecture) MDI (Multiply Dialog Interface) MOF ( NIAM (Nijssen’s Information Analysis
Methodology) OMG (Object
Management Group) OPRR (Object-Property-Role-Relationship) SDI (Single Dialog Interface) UML (Unified Modeling Langue) XMI (XML Metadata Interchange)
Obrázek 15 Diagram tříd – Inserter
Obrázek 16 Diagram tříd - rozdělení tokenů do kategorií
Obrázek 17 Diagram tříd dekorací
Obrázek 18 Diagram tříd balíčku metacase.core.framework.gui.infos C Uživatelská / instalační příručka C.1 Úvodní stránka
Obrázek 19 Úvodní stránka Při startu aplikace se zobrazí úvodní stránka. Tato stránka nabízí základní operace s metaCASE. Uprostřed jsou dvě volby -
přidat CASE
nástroj o nahraje nový CASE z uloženého XML souboru -
vytvořit CASE
nástroj o vytvoří prázdný projekt meta-modelu, který je poté možné vytvářet, až vznikne nový CASE. Po levé straně jsou tři nabídky, pomocí nich je možné se dozvědět aktuální novinky, tipy na práci s aplikací nebo díky zpětné vazbě zaslat zprávu vývojáři. Pokud se chcete vrátit k souboru používaného minule, můžete použít seznam naposledy otevřených souborů vpravo nahoře. Pokud chcete vytvořit schéma za pomoci již vytvořeného meta-modelu, najděte správný meta-model v seznamu a klikněte na vytvořit model. Pokud máte zájem upravit již vytvořený meta-model, je nutné kliknout na otevřít metamodel. Po jeho otevření je možné meta-model upravovat stejným způsobem, jako se vytváří. Výpis meta-modelu je možné filtrovat dle kategorií. K tomu je určena volba změnit v řádce nad seznamem meta-modelů. C.2 Vytvořit nový metamodel Při vytváření meta-modelu je nejprve nutné vytvořit prázdný meta-model. Toho docílíte pomocí volby vytvořit CASE nástroj na úvodní stránce (viz C.1). Poté přibude v pracovním okně průzkumník metamodelu (viz C.3.1) nový meta-model. Ten neobsahuje žádný element, vztah, ani roli. Má jen základní nutné vlastnosti. Meta-model postupně vzniká přidáváním elementů, rolí a vztahu za pomoci kontextového menu v průzkumníku metamodelu (viz C.3.1). Nakonec je často nutné vytvořit skripty, které zajistí funkčnost nástroje (viz 0).
Těmito menu je možné zobrazovat, resp. schovávat jednotlivé panely nástrojů.
Bližší informace o jednotlivých panelech nástrojů naleznete v kapitole C.4. Panely nástrojů se zobrazují v plovoucím režimu bez dekorace dialogového okna (bez rámu).
Každý uzel reprezentující meta-model tedy má několik potomků: - meta-elementy - meta-role - meta-vztahy - meta-vlastnosti (meta-modelu) Všichni tito potomci, kromě meta-vlastností, mohou obsahovat řadu meta-vlastností. Všechny prvky meta-modelu jsou opatřeny kontextovými menu. Díky nim je možné vyvolat editor vzhledu a kódu, vytvořit nový prvek meta-modelu, nastavit typ dat meta-vlastnosti, či nadefinovat vlastnosti meta-vztahů.
Kontextové menu pro meta-model navíc umožňuje vytvořit CASE. To značně zjednodušuje vývoj, kdy lze po každé změně otestovat funkčnost. Bez tohoto průzkumníka není možné vytvořit meta-model, protože v jiné části aplikace není možné provádět výše zmíněné operace.
Role mají význam pouze na úrovni meta-modelu a skriptu. Pomocí tohoto průzkumníka lze upravovat hodnoty jednotlivých vlastností, mazat vztahy a elementy. Výběrem prvku modelu se zvolí patřičný grafický zástupce v editoru. Jeho účel je spíše informativní, protože všechny operace, které nabízí, jsou přístupné z editoru, průzkumníka vlastností (viz C.3.4), nebo standardního panelu nástrojů (viz C.4.1). Veškeré funkce jsou dostupné pomocí kontextových menu, vyvolaných nad patřičnými uzly stromu.
Vkládání se netýká jiných grafických prvků, tzn., že např. dekorace tímto způsobem vložit nejde. Komponenta obsahuje několik záložek. V první se nachází všechny možné vztahy, v druhé všechny elementy. Další záložky odpovídají všem rolím. (Pokud meta-model neobsahuje žádnou meta-roli, bude komponenta obsahovat pouze ony dvě záložky).
Při řazení podle rolí se vloží všechny elementy, které roli dědí
a vztahy, které je možné s nimi navázat.
Zobrazuje soupis všech vlastností a dovoluje jejich změnu. Jedná se jak o povinné (např. body), tak i o volitelné vlastnosti (např. note viz Obrázek 24). Průběžné úpravy hodnot jsou průběžně zobrazovány v editoru. Změny vyvolané editorem (pohyb, změna velikosti aj.) jsou naopak okamžitě promítány do průzkumníka. Některé typy dat vlastností jsou jednoduché a dají se editovat přímo (číslo, bod, řetězec, bod ad.), u ostatních se zobrazuje zástupná komponenta. Skládající se z popisu a tlačítka (…), kterým se vyvolá dialogové okno pro změnu hodnoty.
Obrázek 25 Editor složitějších datových typů C.3.5
Průzkumník metavlastností tvoří obdobu průzkumníka vlastností na úrovni meta-modelu. Jeho použití následuje po zvolení typu dat meta-vlastnosti (viz C.3.1). Každá meta-vlastnost se skládá ze 4 údajů Každé odpovídá jedna záložka: První záložka používá stejný editor jako průzkumník vlastností. Jeho hodnotu bude mít vlastnost po inicializaci. Další tři záložky představují skript volaný při události (po inicializaci, před čtením, po zápisu). Události po inicializaci a po zápisu jsou vhodné pro generování nových hodnot. Událost před čtením je volána před každým použitím, tudíž i před vykreslením. Protože vzhled je pro všechny instance meta-objektu stejný, je nutné nastavit všechny dynamické hodnoty před vykreslením.
Skript se chová podobně jako tělo funkce, tzn., že je zde možné použít konstrukci return (viz C.13.4.12). Hodnota, kterou nese, se poté nastaví patřičné vlastnosti. U jednoduchých operací, např., když vytváříme element pro poznámku v UML, stačí přidat elementu vlastnost, kterou uživatel nastaví text (např. note) a skript bude mít tvar return this.note;. U složitějších výpočtů je vhodné vytvořit výslednou hodnotu za pomoci ostatních událostí (viz C.11). Díky tomu je možné použít při vykreslování podobně jednoduchý kód, jako u poznámky. Klíčové slovo this označuje objekt, ze kterého je skript volán (vztah, element nebo graph).
C.3.6
Při vytváření vzhledu využíváme tzv. panely. Panel představuje obdélníkovou pracovní plochu. U některých návrhů je nutné vložit více textových polí. U nich je složité určit velikost pokud jsou texty generovány skriptem. Proto je možné každý panel rozdělit na dva potomky a vkládat dekorace do každého zvlášť. Výsledná velikost návrhu se poté vypočítává na základě poměru preferovaných velikostí, a tak, pokud je každé textové pole v jiném panelu, zobrazují se texty bez problémů. Aby bylo možné strukturu panelů používat, a vytvářet je nutné využívat průzkumník panelů návrhu. Ten umožňuje strukturu panelu měnit za pomoci kontextových menu (viz nabídky rozdělit vertikálně nebo horizontálně a odstranit potomky). Druhou nutnou funkcí je přepínání panelů v editoru. To se děje automaticky po zvolení některého panelu v průzkumníku.
Do konzole se dále vypisují chyby při sémantickém překladu. Ten probíhá průběžně při změně kódu. Při nalezení chyby smaže konzoly a vypíše hlášku. Konzole obsahuje vlastní panel nástrojů. Tím je možné konzoly
smazat, nebo uložit její obsah do textového souboru.
Element může být potomkem jiného v této reprezentaci, pokud je uvnitř něj. V první úrovni jsou tedy zobrazeny všechny prvky a v dalších mohou být znovu (v jiném kontextu). Při výběru uzlu je zvolen patřičný prvek v editoru.
Zobrazuje soupis všech panelů a umožňuje kliknutím zobrazit, resp. schovat konkrétní panel.
Tento panel nástrojů zahrnuje některé základní funkce: - otevřít o otevře model nebo meta-model ze souboru - uložit o uloží právě zobrazený model do souboru. Pokud nebyl nikdy ukládán, vyvolá dialogové okno pro výběr souboru - tisk o vyvolá standardní dialogové okno pro tisk - náhled o zobrazí náhled tisku (viz C.9) - kopírovat o zkopíruje výběr do schránky (podporuje pouze editor kódu) - vložit o vloží obsah schránky (podporuje pouze editor kódu) - vyjmout o vloží do schránky výběr (podporuje pouze editor kódu)
Obrázek 31 Standardní panel nástrojů Panel slouží pro vložení dekorace do modelu nebo návrhu vzhledu. Použití je jednoduché, kliknutím na dekoraci se zvolí a editor přejde do módu pro vložení dekorace (několik následujících kliknutí do editoru vybere body pro vložení). Vkládání je možné zrušit pomocí tlačítka s ikonou kurzoru myši nebo dvojklikem při vkládání polygonu. Stejnou funkci nabízí nabídka menu vložit – dekorace (viz C.5.3.1)
Obrázek 32 Panel nástrojů – dekorace Panel slouží pro vložení bodu, nebo vektoru do návrhu vzhledu. Použití je jednoduché, kliknutím na dekoraci se zvolí a editor přejde do módu pro vložení dekorace (několik následujících kliknutí do editoru vybere body pro vložení). Vkládání je možné zrušit pomocí tlačítka s ikonou kurzoru myši. Bod představuje místo napojení (viz místo napojení spojnice vztahu v zakončení vztahu). Vektor se používá pouze u vytváření zakončení vztahu, určuje místo spoje zakončení s elementem a směr, jakým má být konec orientován.
Obrázek 33 Ukázka návrhu zakončení Stejnou funkci nabízí nabídka menu vložit – dekorace (viz C.5.3.1)
Obrázek 34 Panel nástrojů - bod, vektor Panel umožňuje vrátit se zpět resp. vpřed při práci s editorem (návrhu, diagramu i kódu). Panel se vztahuje vždy ke komponentě zobrazené v hlavní záložce.
Obrázek 35 Panel nástrojů - vzad, vpřed, Panel přiblížení nabízí uživateli základní operace s velikostí zobrazovaného obsahu editoru. Pomocí něj je možné přibližovat, resp. oddalovat návrh vzhledu, náhledy (meta-modelu, meta-vztahu aj.), náhled tisku i model. Funkce panelu je možné využívat i z roletového menu (viz C.5.2.1).
Obrázek 36 Panel nástrojů – přiblížení Panel umožňuje rychlou práci s textovými poli. Jeho funkce nabízí stejnou funkci jako editor v průzkumníku vlastností (viz C.3.4). Nabízí volbu fontu, velikosti, typu fontu (tučné, kurzíva) a zarovnání horizontální a vertikální.
Obrázek 37 Panel nástrojů – font Panel slouží k interpretaci skriptu. Je aktivní pouze v editoru kódu. Pokud kód neobsahuje detekovatelné chyby (lexikální a sémantický překlad), je aktivní jedno z tlačítek. Interpretovat lze současně pouze jeden kód, nemůže tedy nastat situace, kdy by běžel skript vícekrát. Zastavit interpretaci lze jak za pomoci levého tlačítka, tak i změnou kódu (každá změna kódu vyvolá nový překlad a tudíž zastavení běžícího skriptu).
Obrázek 38 Panel nástrojů – interpret Roletové menu je neoddělitelná součást aplikace. Obsahuje pouze 4 nabídky popsané v následujících kapitolách.
Obrázek 39 Roletové menu
V první části se jedná o načítání XML souborů. Jsou zde dvě nabídky: načtení meta-modelu / modelu. Načíst model znamená otevřít uložené schéma (musí být již načtený patřičný meta-model). Načtení meta-modelu se liší od volby přidat CASE na úvodní stránce (viz C.1) tím, že nezkopíruje meta-model do databáze, a tužíš se neotevře při dalším spuštění aplikace.
Další dvě volby se shodují s nabídkami ve standardním panelu (viz C.4.1). Jsou určeny k tisku obsahu editoru, resp. k vyvolání náhledu tisku (viz C.9). Nabídky import a export jsou popsány v dalších kapitolách (viz C.5.1.1, resp. viz C.5.1.2)
C.5.1.1
Aplikace nenabízí žádné standardní importy (pouze možnost načíst XML soubor generovaný aplikací). Všechny importy jsou tedy definovány konkrétním meta-modelem. To je možné pomocí metody grafu addImport (viz 0). Import se vztahuje k obsahu otevřeného editoru, tzn., každý model může mít různé importy. Pokud nebyl žádný import definován, nebude nabídka aktivní.
C.5.1.2
Menu export je aktivní, pokud je zobrazen nějaký editor. Jeho obsah může být členěn na dvě skupiny. První obsahuje standardní exporty a případná druhá uživatelsky dodefinované exporty v meta-modelu, vytvořené pomocí metody addExport objektu Graph (viz 0).
V současné době aplikace obsahuje pouze jediný standardní export – obrázek. Ten vyvolá dialogové okno pro uložení souboru. Volbou typu souboru může uživatel vybrat výsledný formát (BMP, GIF, PNG nebo JPEG). Výsledný obrázek představuje pracovní plochu bez výběru prvků.
Nabídka úvodní strana přidá úvodní stránku, pokud není zobrazována a zobrazí ji. Volba pravítka umožňuje přidávat, resp. schovávat pravítka (viz C.8).
C.5.2.1 Nabídka zobrazit – přiblížení
- přiblížit o odpovídá tlačítku + v panelu přiblížení (viz C.4.5) - 100% o nastaví přiblížení na 100% (originální rozlišení)
- oddálit o odpovídá tlačítku – v panelu přiblížení (viz C.4.5)
C.5.2.2 Nabídka zobrazit – panely nástrojů
Je shodné s kontextovým menu vyvolaným na nějakém panelu nástrojů nebo hlavním okně (viz C.4).
C.5.2.3 Nabídka zobrazit - pracovní okna
Je shodné s kontextovým menu vyvolaným na nějakém panelu nástrojů nebo hlavním okně (viz C.3).
C.5.3 Nabídka vložit
C.5.3.1 Nabídka vložit – dekorace
- dekorace (viz C.4.2) - bod, vektor (viz C.4.3) Zvolená dekorace je vyznačena pomocí komponenty RadioButton. Zrušit vkládání poté lze volbou zrušit.
C.5.4 Nabídka O programu
Nachází se zde pouze dvě volby: - pro zobrazení nápovědy - pro zobrazení základních informací o aplikaci
C.6 Náhled meta-modelu
Náhled používá pro zobrazení elementů a rolí zástupné symboly. Ty obsahují název a soupis vlastností (povinné jsou v závorkách kurzívou). Mezi rolemi a elementy je naznačena dědičnost a zobrazeny možné vztahy. Každý vztah může být zobrazen vícekrát (pokud je definován pro více dvojic, připojitelných elementů, resp. rolí). Pokud se vztah nezobrazí, ale je definován, může to být způsobeno špatnou definicí. Pokud nejsou nastaveny připojitelné prvky meta-modelu pro jeden z konců vztahu, není možné ji v náhledu zobrazit. Ve výsledném modelu takový vztah použít lze, nicméně nebude napojitelný, a proto je jeho význam sporný. Náhled nedovoluje žádné úpravy z hlediska struktury meta-modelu. Je dovoleno pouze pracovat s rozvržením grafu. Veškeré změny meta-modelu se provádí v průzkumníku metavlastností (viz C.3.5) a průzkumníku metamodelu (viz C.3.1). C.7 Náhled vztahu U každého meta-vztahu je možné zobrazit náhled. V průzkumníku metamodelu lze pravým tlačítkem vyvolat kontextové menu nad meta-vlastností a volbou zobrazit náhled se otevře editor s náhledem. Zobrazený vztah nabízí základní operace pro otestování funkce (zalamování, pohyb).
Obrázek 51 Náhled vztahu
Skládají se ze tří částí: - levý horní roh o přepíná jednotku pravítek § in (palec) § px (pixely)
§ cm (centimetry) - horizontální pravítko - vertikální pravítko Pravítka lze zobrazovat, resp. schovávat najednou, tzn., že nelze mít v stejný moment některé editory s a některé bez pravítek. Jejich užívání se nastavuje pomocí roletového menu (viz C.5.2).
Náhled tisku zahrnuje vlastní panel nástrojů, kterým lze dokument vytisknout, nastavit formát papíru a zobrazit stránku tisku. Zobrazený dokument lze přibližovat, resp. oddalovat stejně jako editor – panelem nástrojů přiblížení (viz C.4.5) nebo roletovým menu (viz C.5.2.1).
C.10 Skript V rámci aplikace se používá podmnožina JavaScriptu (viz další kapitoly). Skriptování se používá na dvou různých místech: - meta-vlastnosti (C.3.5) o používá se pro úpravu vzhledu na základě dat o vyvolává se při událostech § po inicializaci § před čtením § po zápisu - skript pro celý meta-model o vytvoří importy a exporty o obsahuje funkce pro složitější vyhodnocování událostí meta-vlastností Jak již bylo naznačeno, každá meta-vlastnost může mít až tři různé skripty. Každý z nich se pojí s jinou událostí. U všech meta-vlastností, které mají mít svou hodnotu, určenou na základě nějaké jiné (z pravidla uživatelem definované) vlastnosti elementu, resp. vztahu, je nutné použít událost před čtením. Každý vzhled je totiž shodný pro všechny elementy, nebo vztahy stejného druhu. Touto událostí se tedy před každým vykreslením nastaví správná hodnota. Typickým případem je hodnota nápisu v textovém poli, ale obecně se může jednat o jakýkoliv typ dat. V rámci skriptu mohou být použity všechny konstrukce a mohou využívat části skriptu meta-modelu (viz C.12), tzn. metody, proměnné i konstanty. Samotný kód může být složen z libovolného množství příkazů, ale vzhledem k přehlednosti je vhodné výkonnou část napsat v kódu meta-modelu. Pokud chce uživatel měnit hodnotu, musí využít konstrukci return. Její výsledek je poté nastaven jako hodnota. Některé výpočty mohou být složité. V tom případě je vhodné události kombinovat. Příklad: po
inicializaci: this.value=computeValue(); po
zápisu: this.value=computeValue(); před
čtením: return this.value; metoda
v kódu meta-modelu: function computeValue() { var out=”<html>”; // příklad obsahu for (var i=0;i<10;i++) { out+=i; out+=”<br>”; } return out+”</html>”; } Klíčové slovo this zastupuje objekt, v rámci kterého je volán, tzn. buď vztah, element nebo graph.
Kód může obsahovat funkce i osamocené příkazy. Osamocené příkazy je možné použít pro inicializaci modelu (jsou vykonány při vytvoření modelu). Pomocí nich se definují např. importy a exporty.
C.13 Konstrukce skriptu C.13.1 Klíčové slovo Klíčové slovo je řetězec, který je vyhrazen pro konstrukce
skriptu. V implementované podmnožině JavaScriptu jsou použita tato klíčová slova (popis viz další kapitoly):
if, else, function, var, switch, const, case, break, continue, do, while, for, return, default, new, try, catch, throw, finally, this, null. C.13.2 Identifikátor Identifikátor je základní prvek kódu. Jedná se o posloupnost znaků, číslic a podtržítek, které nezačínají číslicí. Identifikátor představuje podmnožinu této definice. Pokud je řetězec klíčovým slovem nejedná se identifikátor. Identifikátor se používá pro pojmenování konstant, proměnných, funkcí, parametrů a dalších konstrukcí s názvem. C.13.3 Literál Literál je taková část kódu, která reprezentuje nějakou hodnotu – konstantu. Může se jednat o číselnou hodnotu, řetězec nebo označení objektu. Literál null označuje prázdný odkaz, a this objekt, ve kterém je použit. C.13.3.1 Číselná hodnota V rámci kódu mohou být dvě různé reprezentace čísla: - celočíselná hodnota - číslo s plovoucí řádovou čárkou Protože skript aplikace je zjednodušením JavaScriptu, je možné využívat pouze dekadickou soustavu. U čísel s plovoucí řádovou čárkou se používá řádová tečka a není povolena konstrukce s exponentem (např. 4.3E+3). C.13.3.2 Řetězec, znak Literál znaku je ve skriptu reprezentován, jako řetězec délky jedna, resp. není mezi nimi rozdíl. Řetězec je možné zapsat dvěma způsoby: - ohraničen apostrofem - ohraničen uvozovkami Může obsahovat escape znaky: - \n - odřádkování - \t - tabulátor - \’ - apostrof - \“ - uvozovky - \r - přesun na začátek řádky - \\ - symbol \ Příklad: Let’s go! “Let\’s go!” “\’\ ” ‘\”\\\’\\\t\”\’ C.13.3.3 Deklarace proměnných a konstant JavaScript neumožňuje definovat typ proměnné, a proto v každé proměnné nebo funkci může být hodnota libovolného typu. Mimo funkce je možné deklarovat konstanty, tedy hodnoty, které nelze v průběhu kódu měnit. Zápis se skládá z klíčového slova const, identifikátoru konstanty, symbolu = a výrazu. Příklad: const PI=3.141528; V rámci kódu se samozřejmě mohou deklarovat proměnné. Jejich zápis se skládá z klíčového slova var, identifikátoru proměnné a případně přiřazovacího příkazu pro inicializaci proměnné. Příklad: var a, b; var c=4-2; var text=“ahoj světe“; C.13.4 Příkazy C.13.4.1 Prázdný příkaz Prázdný příkaz, je příkaz, který nevykoná žádnou operaci. Její syntaxe je jednoduchá - ;. Využívá se u složitějších konstrukcí, v částech, které se musí deklarovat, ale nejsou požadovány. Příklad: ;;;;;;;; // řada prázdných příkazů { příkaz1 … příkazN } Složený příkaz se skládá z posloupnosti příkazů (i nulové délky) a zapisuje se mezi složené závorky. Mohou být v rámci něj deklarovány proměnné. Příklad: {} { var a,b; { ;;; } } Výraz je příkaz, který představuje jakýkoliv aritmetický výpočet. Výraz má výsledek, a ten je možné pomocí přiřazovacího příkazu (viz C.13.4.4) dosadit do nějaké proměnné. Skládá se z posloupností literálů (řetězců, číslic), volání funkcí, závorek a operací. Příklad: var i=3; document.write(6*i+3%2-(5*1.5)); // vypíše : 11.5 Přiřazovací příkaz dovoluje nastavit proměnné hodnotu. Jeho zápis se skládá z identifikátoru proměnné, symbolu přiřazovacího příkazu (=, +=, -=, /=, *=, %=, <<=, >>=, >>>=, |=, &=, ^=) a výrazu. Výraz se nejprve vyhodnotí, a poté pokud je použitý symbol = dosadí do proměnné. V případě jiných symbolů se provede operace (viz začátek symbolu) proměnné s výrazem, a ta se dosadí. Příklad: var a, b; a=5; b=3; b+=a; document.write(a+“,“+b); // vypíše : 5,8 C.13.4.5 Podmíněný příkaz if ( podmínka ) příkaz1 else příkaz2 if ( podmínka ) příkaz1 Vypočítá se podmínka. Je-li výsledkem pravda, provede se příkaz1, jinak pokud existuje, příkaz2. Příklad: if (5>3+2) { document.write(“5 je větší
než 3+ } else document.write(“5 není
větší než 3+ // vypíše : 5 není větší než 3+2 if
(true) { document.write(“ahoj světe“); } // vypíše : ahoj světe switch ( výraz ) { case výraz1 : příkazy1 … case výrazN : příkazyN default: příkazyDef } Příkaz switch představuje zobecněný if. Obsahuje několik celků case a volitelný blok default. Postupně porovnává výraz se všemi výrazy(1..N). Pokud se shodují, začne je postupně vykonávat (poté pokračuje dalším case blokem), dokud nenarazí na příkaz break. Ten vykonávání přeruší. Nebyl-li vykonán žádný case blok, budou vykonány příkazyDef. Příklad: switch (i) { case 0: document.write(0); document.write(0); case 1: document.write(1); break; case
2: document.write(2); default: document.write(3); document.write(3); } /* Při i vypíše 0 001 1 1 2 2 jinak 33 */ C.13.4.7 Ternární výraz podmínka ? výraz1 : výraz2 Vyhodnotí podmínku. Pokud je její hodnota pravda, je výsledkem výraz1, jinak výraz2. C.13.4.8 Volání funkce Volání funkce se skládá z identifikátoru funkce, otevírací závorky, posloupnosti výrazů oddělených čárkami, zavírací závorky a středníku. Každá funkce očekává určitý počet parametrů (viz C.13.4.3). Pokud je při volání zadáno málo parametrů, bude za neudané dosazena hodnota null. Přebytečné parametry budou vyhodnoceny a v rámci výpočtu funkce ignorovány. Příklad: // definice volané funkce function fakt(i) { if (i<0) throw “špatný
argument funkce fakt : i< if (i<2) return 1; return i*fakt(i-1); } document.write(fakt(5)+“,“+fakt(fakt(3))); // vypíše : 120, 720 Příkaz throw vygeneruje výjimku nesoucí nějakou hodnotu. Výjimka může reprezentovat například chybu. Pro práci s výjimkami je určena konstrukce try-catch-finally (C.13.4.10). Příklad: throw “Chyba! Špatný parametr“; throw 4+2; try příkaz1 catch (identifikátor výjimky) příkaz2 finally příkaz3 Konstrukce try-catch-finally se skládá z dvou povinných (try a catch) a jednoho nepovinného (finally) bloku. Nejprve se pokusí vykonat příkaz1. Pokud je během něj generována výjimka pomocí throw (viz C.13.4.9), která není odchycena jinou konstrukcí try-catch-finally, ukončí se její vykonávání a přejde se do bloku catch. Identifikátor výjimky se chová jako deklarace proměnné s hodnotou, kterou nesla výjimka. Blok finally, resp. příkaz3 se provede, ať k výjimce došlo, či nikoliv. Příklad: try { throw “ahoj”; } catch (e) { document.write(e); } finally { document.write(“
světe”); } document.write(“,”); try { 5/0; } catch (e) { document.write(e); } // vypíše : ahoj světe,divide with 0 C.13.4.11 Cykly C.13.4.11.1 for Je implementován pouze základní typ cyklu for: for (příkaz pro inicializaci; podmínka;
výraz pro změnu) příkaz Nejprve se provede příkaz pro inicializaci (může se použít i deklarace proměnné – viz C.13.3.3), poté se provádí dvojice příkaz a výraz pro změnu, dokud se vyhodnocuje podmínka jako pravda. Příklad: for (var i=7; i>=3; i--) dokument.write(i); // vypíše : 76543 C.13.4.11.2 while while (podmínka) příkaz Příkaz se provádí, dokud se podmínka vyhodnocuje jako pravda. Nejprve se testuje podmínka a tak se příkaz nemusí provádět ani jednou. Příklad: var i=10; while (i>0) { document.write(--i); } // vypíše :
9876543210 C.13.4.11.3 do-while do příkaz while (podmínka) Příkaz se provádí, pokud se podmínka vyhodnocuje jako pravda. U cyklu do-while se vždy nejprve provede příkaz a až poté podmínka. Proto se cyklus musí provést alespoň jednou. Příklad: var i=0; do { var j=0; do { document.write(j++); } while (j<5); } while (i!=0); // vypíše : 01234 return výraz; Konstrukce return je určena pro vrácení hodnoty funkce. C.13.4.13 Funkce Funkce je samostatný celek kódu, který může být volán z různých míst. Představuje kus často používaného kódu. Zapíše se, jako posloupnost klíčového slova function, identifikátoru funkce, otevírací závorky, řady identifikátorů (názvů parametrů) oddělených čárkou, uzavírací závorky a bloku. Blok má stejný zápis, jako složený příkaz (viz C.13.4.2). Představuje tělo funkce, tedy část, která je při volání vykonávána. Příkazem return (viz C.13.4.12) je možné vrátit hodnotu – výsledek funkce. Příklad: function showHelloWorld() { document.writeln(“Ahoj
světe”); } function sum(a,b) { return a+b; } function copy(nr, text) { if (nr<0) throw “špatná hodnota parametru copy.nr“; if
(nr==0) return “”; // rekurze – funkce volá sama sebe return text+copy(nr-1,text); } showHelloWorld(); document.writeln(sum(4,8)); document.writeln( /* vypíše: Ahoj světe 12 …… */ C.13.4.14 break Příkaz break ukončí předčasně vykonávání cyklu. Může být využit i uvnitř příkazu switch (viz C.13.4.6). Příklad: for (var i=0;i<5;i++)
{ document.write(i); break; document.write(”!!”); } // vypíše : 0 C.13.4.15 continue Příkaz continue ukončí předčasně tělo cyklu, ale cyklus bude pokračovat. Příklad: for (var i=0;i<5;i++)
{ document.write(i); continue; document.write(”!!”); } // vypíše : 01234 C.13.4.16 new Jedná se o klíčové slovo, které vytváří objekt. Objektem může být libovolná metoda. Při vytváření vlastního objektu se definují proměnné a funkce objektu pomocí klíčového slova this. Příklad: function _show() { document.write(this.sum); } function _add(i) { return this.sum+=i; } function counter() { this.sum=0; this.show=_show; this.add=_add; } var a=new
counter(), b=new counter(); a.add(4); a.add(3); b.add(7); b.add(9); a.show(); document.write(“,”); b.show(); // vypíše : 7,16 C.13.5 Předefinované metody createGraph(name) Vytvoří a vrátí instanci meta-modelu (model) s názvem name. alert(text) Vyvolá informativní dialogové okno s textem text. prompt(text, value) Vyvolá dialogové okno pro získání uživatelského vstupu se zprávou text a přednastavenou hodnotou value (nepovinný parametr, při nezadání bude použit prázdný řetězec) confirm(text) Vyvolá dialogové okno s otázkou text a volbami ano a ne. Výsledkem metody je hodnota typu boolean (ano=true, ne a zavření dialogu=false) isNaN(value) Vrátí true pokud není value číslo (viz not a number u čísel s plovoucí čárkou) isFinite(value) Vrátí true, pokud je value končené číslo (není nekonečno) parseFloat(text) Převede řetězec text na číslo s plovoucí čárkou. parseInt(text) Převede řetězec text na celočíselnou hodnotu. C.13.6 Objekt Math C.13.6.1 Funkce Math.abs(i) Vrátí absolutní hodnotu čísla i. Příklad: document.write(Math.abs(-4)); // vypíše : 4 Math.exp(i) Vrátí hodnotu ei. Příklad: document.write(Math.exp(2)); // vypíše : 7,3890560989306502274463271505434 Math.log(i) Vrátí hodnotu přirozeného logaritmu – ln(i). Příklad: document.write(Math.log(10)); // vypíše : 2,3025850929940456840179914546844 Math.max(a,b) Vrátí vyšší hodnotu z a a b. Příklad: document.write(Math.max(-4,6)); // vypíše : 6 Math.min(a,b) Vrátí menší hodnotu z a a b. Příklad: document.write(Math.min(-4,6)); // vypíše : -4 Math.pow(a,b) Vrátí hodnotu ab. Příklad: document.write(Math.pow(2,10)); // vypíše : 1024 Math.random() Vrátí náhodné číslo s plovoucí čárkou na intervalu <0,1>. Math.sqrt(i) Vrátí druhou odmocninu z čísla i. Příklad: document.write(Math.sqrt(16)); // vypíše : 4 Math.ceil(i) Pokud má číslo i desetinnou část (není celé číslo) vrátí vyšší celé číslo. Příklad: document.write(Math.ceil(4.5)); // vypíše : 5 Math.floor(i) Pokud má číslo i desetinnou část (není celé číslo) vrátí celočíselnou hodnotu. Příklad: document.write(Math.floor(4.5)); // vypíše : 4 Math.round(i) Vrátí zaokrouhlené číslo i. Příklad: document.write(Math.floor(4.5)); // vypíše : 5 Math.acos(i) Vrátí arccos(i). Math.asin(i) Vrátí arcsin(i). Math.atan(i) Vrátí arctg(i). Math.atan2(x,y) Vrátí úhel v radiánech od osy x do bodu [x,y]. Math.cos(i) Vrátí cos(i). Math.sin(i) Vrátí sin(i). Math.tan(i) Vrátí tg(i). C.13.6.2 Kontanty Math.E Základ přirozeného logaritmu Math.LN10 Přirozený logaritmus 10 – ln(10) Math.LN2 Přirozený logaritmus 2 – ln(2) Math.LN10E Desítkový logaritmus e – log10(e) Math.LN2E Dvojkový logaritmus e – log2(e) Math.PI Hodnota π (s přesností double). Math.SQRT2 Odmocnina z 2. Math.SQRT1_2 Odmocnina z ½. C.13.7 Objekt dokument C.13.7.1 Funkce document.write(text) Vypíše do konzole řetězec text. document.writeln(text) Vypíše do konzole řetězec text a odřádkuje. C.13.8 Objekt String C.13.8.1 Funkce length() Vrátí délku řetězce. Příklad: document.write(“ahoj svete“.length()); // vypíše : 10 toLowerCase() Vrátí řetězec převedený na malá písmena. Příklad: document.write(“aBcD“.toLowerCase()); // vypíše : abcd toUpperCase() Vrátí řetězec převedený na velká písmena. Příklad: document.write(“aBcD“.toLowerCase()); // vypíše : ABCD toString() Vrátí kopii řetězce. Příklad: document.write(“aBcD“.toLowerCase()); // vypíše : aBcD charAt(i) Vrátí i-tý znak řetězce. Příklad: document.write(“aBcD“.charAt(3)); // vypíše : D charCodeAt(i) Vrátí číselnou hodnotu i-tého znaku řetězce. Příklad: document.write(“aBcD“.charCodeAt(1)); // vypíše : 66 subString(a,b) Vrátí řetězec začínající na indexu a a konče na indexu b (bez b-tého znaku). Příklad: document.write(“aBcD“.subString(1,3)); // vypíše : Bc substr(a,b) Vrátí řetězec délky b začínající na indexu a. Příklad: document.write(“aBcD“.substr(1,2)); // vypíše : Bc indexOf(text) Vrátí index, na kterém se objevuje první výskyt řetězce text. Pokud takový index neexistuje, je výsledkem funkce -1. Příklad: document.write(“abababa“.indexOf(ba)); // vypíše : 1 lastIndexOf(text) Vrátí index, na kterém se objevuje poslední výskyt řetězce text. Pokud takový index neexistuje, je výsledkem funkce -1. Příklad: document.write(“abababa“.lastIndexOf(ba)); // vypíše : 5 C.13.9 Objekt FileWriter C.13.9.1 Konstruktor Konstruktor může mít jeden parametr. Ten určuje soubor, který se má otevřít. Pokud soubor není zadán, vyvolá se dialogové okno pro výběr souboru. C.13.9.2 Funkce close() Uzavře výstupní proud pro zápis dat. write(i) Pokud je i - pole o zapíše postupně všechny jeho hodnoty bez oddělovačů. o pro zápis hodnot pole používá stejná pravidla jako pro funkci write - celočíselná hodnota o zapíše znak s kódem i - řetězec o zapíše řetězec writeln(i) Provede write(i) (viz 0) a odřádkuje. C.13.10 Objekt FileReader C.13.10.1 Konstruktor Konstruktor může mít jeden parametr. Ten určuje soubor, který se má otevřít. Pokud soubor neexistuje, nebo není zadán, vyvolá se dialogové okno pro výběr souboru. C.13.10.2 Funkce close() Uzavře vstupní proud pro čtení dat. read() Přečte znak a vrátí jeho kód. Pokud byl soubor přečten celý vrátí -1. readLine() Přečte řádku ze souboru a vrátí ji jako řetězec. Pokud byl soubor přečten celý, vrátí null. skip(i) Přeskočí i znaků ve čteném souboru. C.13.11 Objekt Graph (diagram) C.13.11.1 Funkce getElements() Vrátí pole elementů, které diagram obsahuje. getRelationships() Vrátí pole vztahů, které diagram obsahuje. getRoles() Vrátí pole rolí, které diagram obsahuje. createElement(name) Vytvoří nový element podle jména meta-elementu name. createRelationships(name) Vytvoří nový vztah podle jména meta-vztahu name. addImport(name, fce) Přidá import diagramu se jménem name. Při vyvolání importu bude zavolána funkce, určená parametrem fce. Při zpětném volání bude zadán parametr, obsahující diagram, ze kterého byl volán. Příklad: function importA(graph) { document.write(“importuj
do ” + graph.getName()); } addImport(“ukázkový import“,importA); addExport(name, fce) Přidá export diagramu se jménem name. Při vyvolání exportu bude zavolána funkce, určená parametrem fce. Při zpětném volání bude zadán parametr, obsahující diagram, ze kterého byl volán. Příklad: function exportA(graph) { document.write(“exportuj
z ” + graph.getName()); } addImport(“ukázkový export“,exportA); C.13.12 Objekt Relationship C.13.12.1 Funkce getEnd(i) Vrátí i-tý (0,1) konec vztahu. C.13.12.2 Proměnné end Obsahuje pole s konci vztahu C.13.13 Objekt End C.13.13.1 Funkce connectTo(elm) Připojí konec k elementu elm. disconnect() Odpoj zakončení, je-li připojen k nějakému elementu. getConnected() Vrátí element, ke kterému je konec připojen. Není-li, vrátí null. C.13.14 Typ dat vektor C.13.14.1 Funkce size() Vrátí počet prvků vektoru get(i) Vrátí i-tý prvek vektoru. remove(i) Odstraní i-tý prvek vektoru. set(i, value) Nastaví jako i-tý prvek hodnotu value. add(value) Přidá na konec vektoru prvek value. C.13.15 Objekt Array – pole C.13.15.1 Funkce lenght Vrátí délku pole.
D Přílohy skriptovacího jazyka D.1 Gramatika codeà const1 codeà var ; code codeà function code codeà command ; code const1à const identifikátor = term const2 const2à , identifikátor = term const2 const2à ; functionà function identifikátor ( functionVar ) block functionà ε functionVarà identifikátor
functionVar2 functionVar2à , identifikátor
functionVar2 functionVar2à ε commandà block commandà call commandà assign commandà term commandà if commandà for commandà while commandà do commandà var commandà ; commandà return commandà throw1 commandà try1 blockà { block2 block2à command ; block2 block2à } callà getter identifikátor ( callTerm
) callTermà ε callTermà term callTerm2 callTerm2à , term callTerm2 callTerm2à ε assignà getter identifikátor
= term if1à if ( term ) command if2 if2à else command if2à ε for1à for ( command ; term ; command ) command while1à while ( term ) command do1à do command while ( term ) varà var <ident> var2 var3 var2à = term var3à , identifikátor var2 var3à ε returnà return ; returnà return term ; geterà identifikátor . termà t2 t1 termà [ t26 ] t1à ? term : term t1à ε t2à t4 t3 t3à || t4 t3 t3à ε t4à t6 t5 t5à && t6
t5 t5à ε t6à t8 t7 t7à | t8 t7 t7à ε t8à t10 t9 t9à ^ t10 t9 t9à ε t10à t12 t11 t11à & t12
t11 t11à ε t12à t14 t13 t13à == t14 t13 t13à != t14 t13 t13à === t14 t13 t13à !== t14 t13 t13à ε t14à t16 t15 t15à < t16
t15 t15à <= t16
t15 t15à > t16
t15 t15à <= t16
t15 t15à ε t16à t18 t17 t17à << t18
t17 t17à >> t18
t17 t17à >>> t18
t17 t17à ε t18à t20 t19 t19à + t20 t19 t19à - t20 t19 t19à ε t20à t22 t21 t21à * t22 t21 t21à / t22 t21 t21à % t22 t21 t21à ε t22à ++ <ident> t22à -- <ident> t22à - t23 t22à ~ t23 t22à ! t23 t22à t23 t23à ( term ) t23à literál t25 t23à identifikátor t25
t24 t23à call t25 t23à new identifikátor t24à ++ t24à -- t24à [ term ] t25 t25à . call t25à . identifikátor t25à ε t26à term t27 t26à ε t27à , term t27 t27à ε D.2 Předefinované metody createGraph(name) Vytvoří a vrátí instanci meta-modelu (model) s názvem name. alert(text) Vyvolá informativní dialogové okno s textem text. prompt(text, value) Vyvolá dialogové okno pro získání uživatelského vstupu se zprávou text a přednastavenou hodnotou value (nepovinný parametr, při nezadání bude použit prázdný řetězec) confirm(text) Vyvolá dialogové okno s otázkou text a volbami ano a ne. Výsledkem metody je hodnota typu boolean (ano=true, ne a zavření dialogu=false) isNaN(value) Vrátí true pokud není value číslo (viz not a number u čísel s plovoucí čárkou) isFinite(value) Vrátí true, pokud je value končené číslo (není nekonečno). parseFloat(text) Převede řetězec text na číslo s plovoucí řádovou čárkou. parseInt(text) Převede řetězec text na celočíselnou hodnotu. D.3 Objekt Math D.3.1 Funkce Math.abs(i) Vrátí absolutní hodnotu čísla i. Math.exp(i) Vrátí hodnotu ei. Math.log(i) Vrátí hodnotu přirozeného logaritmu – ln(i). Math.max(a,b) Vrátí vyšší hodnotu z a a b. Math.min(a,b) Vrátí menší hodnotu z a a b. Math.pow(a,b) Vrátí hodnotu ab. Math.random() Vrátí náhodné číslo s plovoucí čárkou na intervalu <0,1>. Math.sqrt(i) Vrátí druhou odmocninu z čísla i. Math.ceil(i) Pokud má číslo i desetinnou část (není celé číslo) vrátí vyšší celé číslo. Math.floor(i) Pokud má číslo i desetinnou část (není celé číslo) vrátí celočíselnou hodnotu. Math.round(i) Vrátí zaokrouhlené číslo i. Math.acos(i) Vrátí arccos(i). Math.asin(i) Vrátí arcsin(i). Math.atan(i) Vrátí arctg(i). Math.atan2(x,y) Vrátí úhel v radiánech od osy x do bodu [x,y]. Math.cos(i) Vrátí cos(i). Math.sin(i) Vrátí sin(i). Math.tan(i) Vrátí tg(i). D.3.2 Konstanty Math.E Základ přirozeného logaritmu Math.LN10 Přirození logaritmus 10 – ln(10) Math.LN2 Přirozený logaritmus 2 – ln(2) Math.LN10E Desítkový logaritmus e – log10(e) Math.LN2E Dvojkový logaritmus e – log2(e) Math.PI Hodnota π (s přesností double). Math.SQRT2 Odmocnina z 2. Math.SQRT1_2 Odmocnina z ½. D.4 Objekt Dokument D.4.1 Funkce document.write(text) Vypíše do konzole řetězec text. document.writeln(text) Vypíše do konzole řetězec text a odřádkuje. D.5 Objekt String D.5.1 Funkce length() Vrátí délku řetězce. toLowerCase() Vrátí řetězec převedený na malá písmena. toUpperCase() Vrátí řetězec převedený na velká písmena. toString() Vrátí kopii řetězce. charAt(i) Vrátí i-tý znak řetězce. charCodeAt(i) Vrátí číselnou hodnotu i-tého znaku řetězce. subString(a,b) Vrátí řetězec začínající na indexu a a konče na indexu b (bez b-tého znaku). substr(a,b) Vrátí řetězec délky b začínající na indexu a. indexOf(text) Vrátí index, na kterém se objevuje první výskyt řetězce text. Pokud takový index neexistuje, je výsledkem funkce -1. lastIndexOf(text) Vrátí index, na kterém se objevuje poslední výskyt řetězce text. Pokud takový index neexistuje, je výsledkem funkce -1. D.6 Objekt FileWriter D.6.1 Konstruktor Konstruktor může mít jeden parametr. Ten určuje soubor, který se má otevřít. Pokud soubor není zadán, vyvolá se dialogové okno pro výběr souboru. D.6.2 Funkce close() Uzavře výstupní proud pro zápis dat. Pokud je i - pole o zapíšou se postupně všechny jeho hodnoty bez oddělovačů. o pro zápis hodnot pole používá stejná pravidla jako pro funkci write - celočíselná hodnota o zapíše znak s kódem i - řetězec o zapíše řetězec writeln(i) Provede write(i) (viz 0) a odřádkuje. D.7 Objekt FileReader D.7.1 Konstruktor Konstruktor může mít jeden parametr. Ten určuje soubor, který se má otevřít. Pokud soubor neexistuje nebo není zadán, vyvolá se dialogové okno pro výběr souboru. D.7.2 Funkce close() Uzavře vstupní proud pro čtení dat. read() Přečte znak a vrátí jeho kód. Pokud byl soubor přečten celý, vrátí -1. readLine() Přečte řádku ze souboru a vrátí jako řetězec. Pokud byl soubor přečten celý, vrátí null. skip(i) Přeskočí i znaků ve čteném souboru. D.8 Objekt Graph (diagram) D.8.1 Funkce getElements() Vrátí pole elementů, které diagram obsahuje. getRelationships() Vrátí pole vztahů, které diagram obsahuje. getRoles() Vrátí pole rolí, které diagram obsahuje. createElement(name) Vytvoří nový element podle jména meta-elementu name. createRelationships(name) Vytvoří nový vztah podle jména meta-vztahu name. addImport(name, fce) Přidá import diagramu se jménem name. Při vyvolání importu bude zavolána funkce určená parametrem fce. Při zpětném volání bude zadán parametr obsahující diagram, ze kterého byl volán. addExport(name, fce) Přidá export diagramu se jménem name. Při vyvolání exportu bude zavolána funkce určená parametrem fce. Při zpětném volání bude zadán parametr obsahující diagram, ze kterého byl volán. D.9 Objekt Relationship D.9.1 Funkce getEnd(i) Vrátí i-tý (0,1) konec vztahu. D.9.2 Proměnné end Obsahuje pole s konci vztahu D.10 Objekt End D.10.1 Funkce connectTo(elm) Připojí konec k elementu elm. disconnect() Odpojí zakončení, je-li připojen k nějakému elementu. getConnected() Vrátí element, ke kterému je konec připojen. Není-li, vrátí null. D.11 Typ dat vektor D.11.1 Funkce size() Vrátí počet prvků vektoru get(i) Vrátí i-tý prvek vektoru. remove(i) Odstraní i-tý prvek vektoru. set(i, value) Nastaví jako i-tý prvek hodnotu value. add(value) Přidá na konec vektoru prvek value. D.12 Objekt Array – pole D.12.1 Funkce lenght() Vrátí délku pole. E Ukázky schémat vzniklých aplikací metaCASE V diplomové práci byla použita některá schémata vytvořená pomocí mé aplikace (viz Obrázek 7, Obrázek 8, Obrázek 12, Obrázek 50). V této příloze naleznete některé další ukázky uložené v adresáři examples. E.1 ER-schéma
Obrázek 55 Ukázka ER-schéma Vygenerovaný export INIT
SCRIPT =========== DROP
TABLE dtb.entitička; CREATE
TABLE dtb.entitička( CONSTRAINT entitička_pkey PRIMARY KEY () ) DROP
TABLE dtb.entity; CREATE
TABLE dtb.entity( JOP text, attribute2 varchar(4) NOT NULL, atribute1 float NOT NULL, poviny int NOT NULL CONSTRAINT entity_pkey PRIMARY KEY
(attribute2, atribute1) ) DROP
TABLE dtb.podtyp; CREATE
TABLE dtb.podtyp( attribute2 varchar(4) NOT NULL atribute1 float NOT NULL attribute3 int8 CONSTRAINT entity_pkey PRIMARY KEY
(attribute2, atribute1) ) DROP
TABLE dtb.relace; CREATE
TABLE dtb.relace( attribute2 varchar(4) NOT NULL atribute1 float NOT NULL active bool NOT NULL CONSTRAINT relace_pkey PRIMARY KEY
(attribute2,atribute1) ) ALTER
TABLE dtb.relace ADD CONSTRAINT attribute2_fkey FOREIGN KEY attribute2_fkey
(relace) REFERENCES attribute2 (dtb.entity) ALTER
TABLE dtb.relace ADD CONSTRAINT atribute1_fkey FOREIGN KEY atribute1_fkey
(relace) REFERENCES atribute1 (dtb.entity) ALTER
TABLE dtb.podtyp ADD CONSTRAINT attribute2_fkey FOREIGN KEY attribute2_fkey
(podtyp) REFERENCES attribute2 (dtb.entity) ALTER
TABLE dtb.podtyp ADD CONSTRAINT atribute1_fkey FOREIGN KEY atribute1_fkey
(podtyp) REFERENCES atribute1 (dtb.entity) E.2 Use-case
Obrázek 56 Ukázka schéma use-case E.3 Diagram tříd UML
Obrázek 57 Ukázka drigramu tříd
created by REE-systems
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

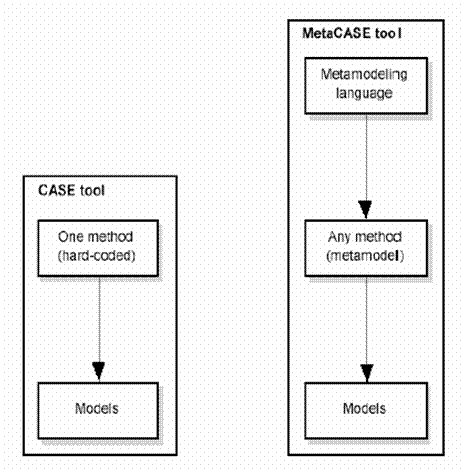
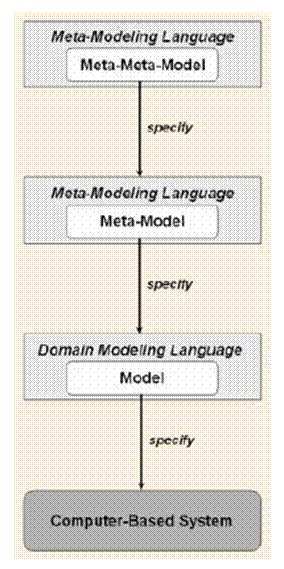
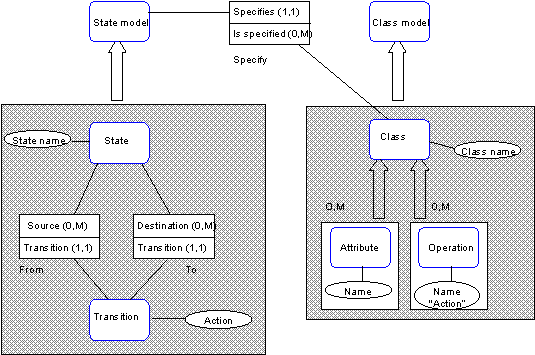
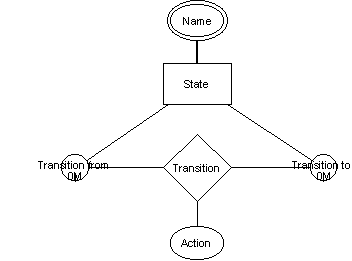
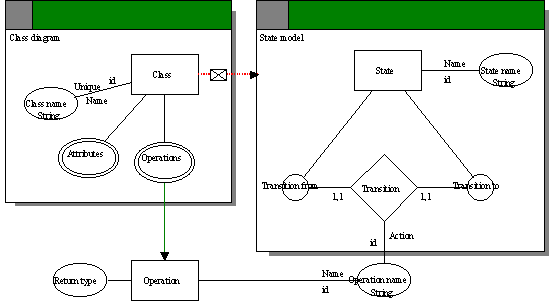
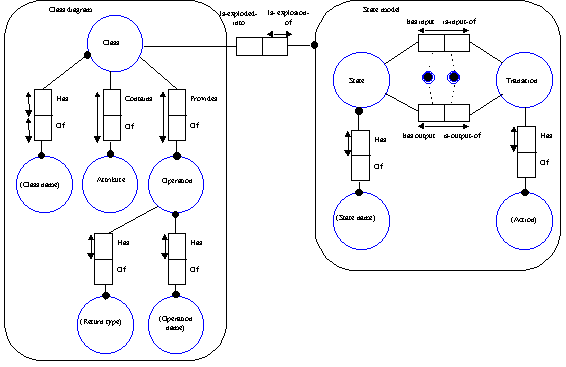
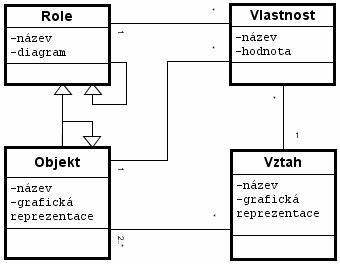
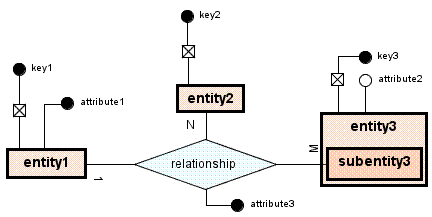
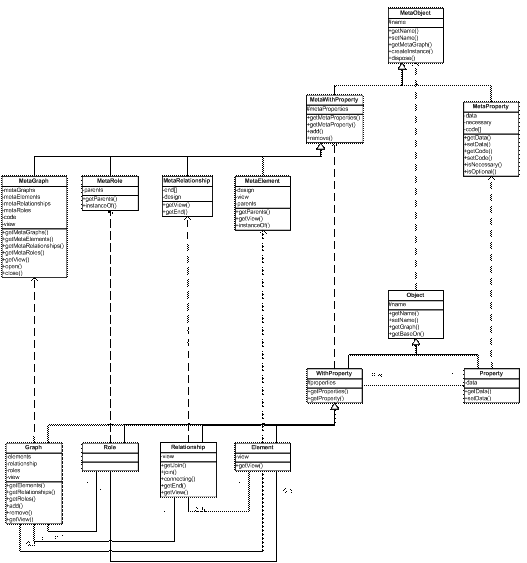
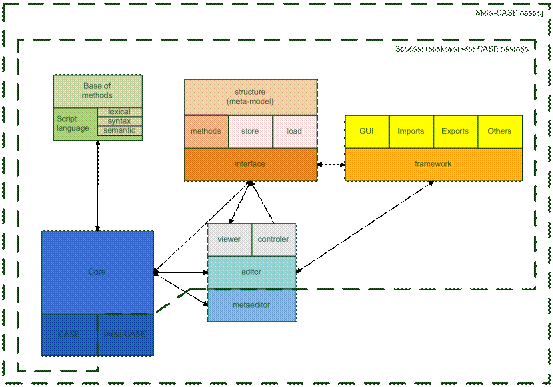
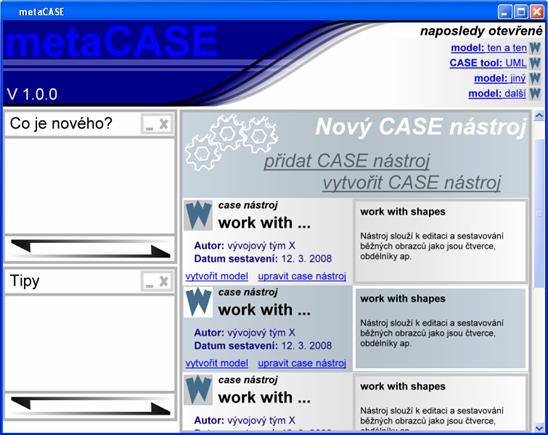

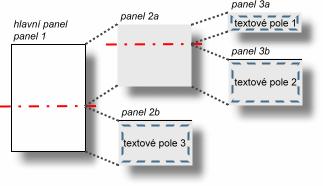
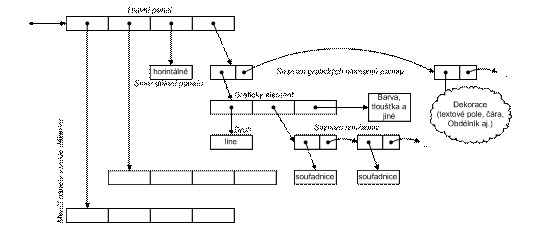
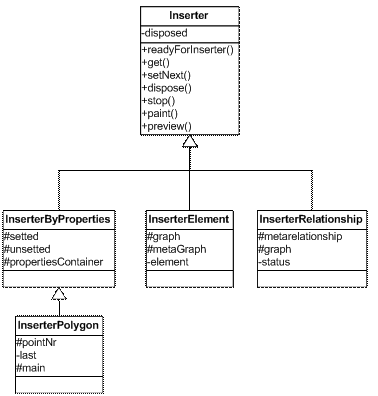
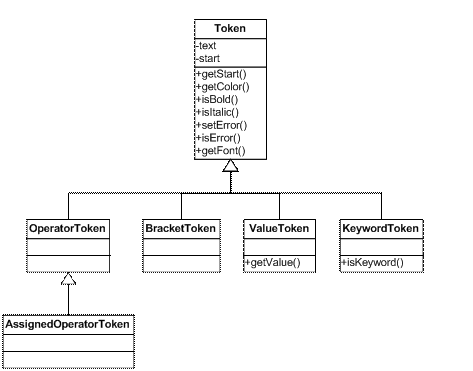
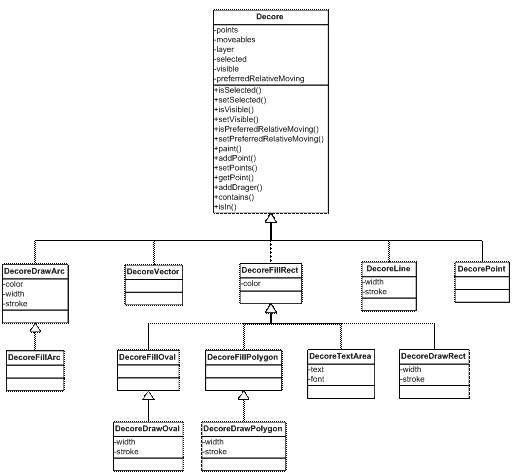
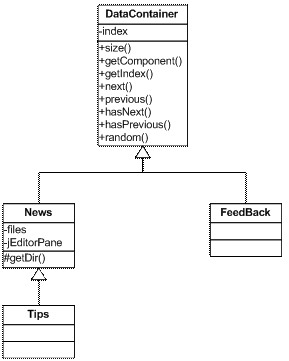
 Pracovní
okna se ovládají pomocí kontextového menu na hlavním okně nebo na některé
pracovní liště. Další možností je využít roletové menu (viz
Pracovní
okna se ovládají pomocí kontextového menu na hlavním okně nebo na některé
pracovní liště. Další možností je využít roletové menu (viz  Průzkumník
metamodelu má za úkol zobrazovat všechny otevřené meta-modely a jejich
strukturu.
Průzkumník
metamodelu má za úkol zobrazovat všechny otevřené meta-modely a jejich
strukturu.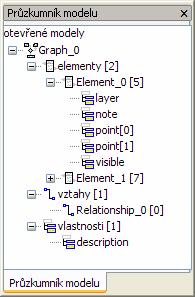 Průzkumník
modelu je obdoba průzkumníka metavlastností (viz
Průzkumník
modelu je obdoba průzkumníka metavlastností (viz 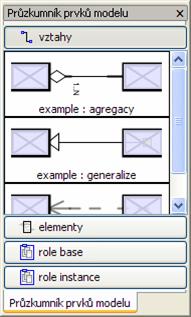 Tento
průzkumník je nezbytný pro vytváření modelu (schéma). Pomocí této komponenty se
dají do modelu vkládat elementy a vztahy. Jedná se o jediný způsob, jak je
vložit.
Tento
průzkumník je nezbytný pro vytváření modelu (schéma). Pomocí této komponenty se
dají do modelu vkládat elementy a vztahy. Jedná se o jediný způsob, jak je
vložit.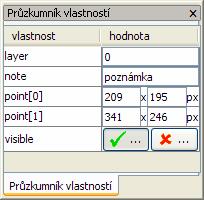 Průzkumník
vlastností pracuje s grafickým prvkem, který je v editoru vybrán,
nebo s diagramem.
Průzkumník
vlastností pracuje s grafickým prvkem, který je v editoru vybrán,
nebo s diagramem.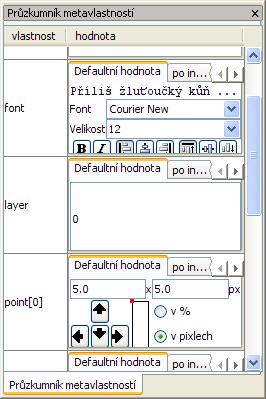
 Konzole
je jednoduché pracovní okno, které slouží pro standardní výstup (metody document.write a document.writeln viz
Konzole
je jednoduché pracovní okno, které slouží pro standardní výstup (metody document.write a document.writeln viz  Průzkumník
modelů zobrazuje stromovou strukturu všech dekorací, vztahů a elementů.
Průzkumník
modelů zobrazuje stromovou strukturu všech dekorací, vztahů a elementů. Kontextové
menu pro správu panelů nástrojů je možné vyvolovat stiskem pravého tlačítka nad
hlavním oknem aplikace nebo nad volným prostorem jakéhokoliv panelu nástrojů.
Kontextové
menu pro správu panelů nástrojů je možné vyvolovat stiskem pravého tlačítka nad
hlavním oknem aplikace nebo nad volným prostorem jakéhokoliv panelu nástrojů.
 Nabídka
soubor nabízí základní funkce pro práci s aplikací.
Nabídka
soubor nabízí základní funkce pro práci s aplikací.
 Nabídka
zobrazit zahrnuje menu přiblížení, panely nástrojů a pracovní okna. Ty jsou popsány
v dalších kapitolách a přístupné i jiným způsobem, než jen z roletového
menu.
Nabídka
zobrazit zahrnuje menu přiblížení, panely nástrojů a pracovní okna. Ty jsou popsány
v dalších kapitolách a přístupné i jiným způsobem, než jen z roletového
menu. Tato
nabídka obsahuje tři možné volby:
Tato
nabídka obsahuje tři možné volby: Pomocí
tohoto menu je možné zobrazovat, resp. schovávat všechny panely nástrojů.
Pomocí
tohoto menu je možné zobrazovat, resp. schovávat všechny panely nástrojů. Pomocí
tohoto menu je možné zobrazovat, resp. schovávat všechna pracovní okna.
Pomocí
tohoto menu je možné zobrazovat, resp. schovávat všechna pracovní okna. Obsahuje
volby pro každou dekoraci zvlášť a volbu zrušit. Funkcí odpovídá dvojice
panelů nástrojů:
Obsahuje
volby pro každou dekoraci zvlášť a volbu zrušit. Funkcí odpovídá dvojice
panelů nástrojů: Poslední
nabídka roletového menu je určena pro informace o aplikaci.
Poslední
nabídka roletového menu je určena pro informace o aplikaci.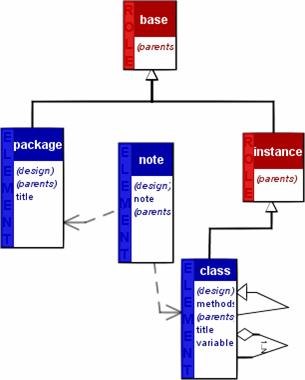 Náhled
meta-modelu je možné vyvolat z průzkumníka metamodelu (viz
Náhled
meta-modelu je možné vyvolat z průzkumníka metamodelu (viz 
 Pravítka
jsou grafické komponenty, které je možné zobrazovat v každém editoru a
náhledu tisku.
Pravítka
jsou grafické komponenty, které je možné zobrazovat v každém editoru a
náhledu tisku. Pro
každý editor (modelu – CASE, náhledy) je možné zobrazit náhled tisku za pomoci
standardního panelu nástrojů (viz
Pro
každý editor (modelu – CASE, náhledy) je možné zobrazit náhled tisku za pomoci
standardního panelu nástrojů (viz  Každý
meta-model má povinnou meta-vlastnost code.
Při vyvolání kontextového menu nad ní, je možné pomocí volby zobrazit editor kód otevřít a následně
editovat (viz
Každý
meta-model má povinnou meta-vlastnost code.
Při vyvolání kontextového menu nad ní, je možné pomocí volby zobrazit editor kód otevřít a následně
editovat (viz